VWAP Reversion (Sequential Stats + Profit/Loss Points)First time posting. This is my attempt to evaluate the effectiveness of VWAP reversion. I decided to make this an indicator with its own integrated stats.
If you set the session length to lets say 100, but choose a 1 minute timeframe, it will only load as many sessions as the chart will allow for that timeframe. increasing the timeframe will allow you to go back further with more sessions.
I plan to implement more and more as I refine it. I just wanted to get my working copy out into the universe. I'd like to add some method of "scaling in". Perhaps if the price goes further and further away from the original entry, say for each additional std. deviation band further, it could add another entry signal.
My trading journey is just beginning, I've never coded before, and this was made entirely through the fusion of my attempt to communicate the ideas in my head for ChatGPT to turn into code!
Bandes et canaux

Overnight Time Box Overnight Time Box (22:59 → 09:59, minutes & TZ)
Automatically draws a time-based box for a customizable window that can cross midnight. Perfect for marking the overnight range up to London open (e.g., 22:59–09:59 in Europe/Bucharest), but works with any minute-level window.
What it does
Builds a daily box covering all price action between two user-defined times (e.g., 22:59 → 09:59).
Tracks session High/Low in real time and can plot extended HL lines for reference.
Keeps historical boxes on the chart for backtesting and review (no flicker, no errors).
How to use
Add the script to an intraday chart.
Configure:
Time zone (default: Europe/Bucharest).
Interval (HHMM-HHMM) — e.g., 2259-0959 (minutes supported).
Optional: High/Low lines, fill color, border color, line width.
Use on intraday timeframes (M1–H4).
Note: On Daily/Weekly/Monthly, a heads-up label reminds you it’s designed for intraday use.
Inputs
Time zone: correct DST handling.
Interval (HHMM-HHMM): supports windows that span midnight.
Draw High/Low lines: extended HL guides for the session.
Colors & widths: full visual customization.
Use cases
Mark the overnight range into London open (10:00 RO).
Delimit Killzones / ICT Silver Bullet windows.
Study range, liquidity raids, FVGs before major sessions.
Tech notes
Built on Pine Script v5 using input.session → stable, DST-safe.
Increased max_boxes_count / max_lines_count to preserve history.
Boxes are “frozen” at session end and remain on chart.
Limitations
Intended for intraday only.
One interval per script instance; attach multiple instances for multiple windows.

NSR - Dynamic Linear Regression ChannelOverview
The NSR - Dynamic Linear Regression Channel is a powerful overlay indicator that plots a dynamic regression-based channel around price action. Unlike static channels, this tool continuously recalculates the linear regression trendline from a user-defined starting point and builds upper and lower boundaries using a combination of standard deviation and maximum price deviations (highs/lows).
It visually separates "Premium" (overvalued) and "Discount" (undervalued) zones relative to the regression trend — ideal for mean-reversion, breakout, or trend-following strategies.
Key Features
Dynamic Regression Line Calculates slope, intercept, and average using full lookback from a reset point.
Adaptive Channel Width Combines standard deviation of residuals with max high/low deviations for robust boundaries.
Auto-Reset on Breakout Channel resets when price closes beyond upper/lower band twice in direction of trend .
Visual Zones Blue shaded = Premium (resistance zone)
Red shaded = Discount (support zone)
Real-Time Updates Live channel extends with each bar; historical channels preserved on reset.
How It Works
Regression Calculation
Uses all bars since last reset to compute the best-fit line:
y = intercept + slope × bar_position
Deviation Bands
Statistical : Standard deviation of price from regression line
Structural : Maximum distance from highs to line (upper) and lows to line (lower)
Final band = Regression Line ± (Deviation Input × StdDev)
Channel Reset Logic
Resets when:
Price closes above upper band twice in an uptrend (slope > 0)
OR closes below lower band twice in a downtrend (slope < 0)
Prevents overextension and adapts to new trends.
Visual Output
Active channel updates in real-time
Completed channels saved as historical reference (up to 500 lines/boxes)
Input Parameters
Deviation (2.0) - Multiplier for standard deviation to set channel width
Premium Color - blue color for upper (resistance) zone
Discount Color - red color for lower (support) zone
Best Use Cases
Mean Reversion - Buy near lower band in uptrend, sell near upper band
Breakout Trading - Enter on confirmed close beyond band + volume
Trend Confirmation - Use slope direction + price position in channel
Stop Loss / Take Profit - Place stops beyond opposite band
Pro Tips
Use on higher timeframes (4H, Daily) for cleaner regression fits
Combine with volume or momentum to filter false breakouts
Lower Deviation (e.g., 1.5) for tighter, more responsive channels
Watch channel resets — they often mark significant trend shifts
Why Use DLRC?
"Most channels are static. This one evolves with the market."
The NSR-DLRC gives you a mathematically sound, visually intuitive way to see:
Where price should be (regression)
Where it has been (deviation extremes)
When the trend is breaking structure
Perfect for traders who want regression-based precision without rigid assumptions.
Add to chart → Watch price dance within the evolving trend corridor.

MIG and MC 发布简介(中文)
MIG and MC 指标帮助日内交易者快速识别微型缺口(Micro Gap)与微型通道(Micro Channel)。脚本支持过滤开盘跳空、合并连续缺口,并自动绘制
FPL(Fair Price Line)延伸线,既可追踪缺口是否被填补,也能直观标注潜在的趋势结构。为了确保跨周期一致性,最新版本对开盘前后和跨日场景做了专门处理
主要特性
- 自动检测并显示看涨/看跌微型缺口,支持按需合并连续缺口。
- 自定义是否忽略开盘缺口、缺口显示范围与 FPL 样式。
- FPL 触及后即停止延伸,辅助研判缺口是否真正回补。
- 内置强收盘与缺口过滤的微型通道识别,可选多种严格程度。
- 适用于 1/5/9 分钟等日内周期,也适用于更长周期。
Recommended English Description
The MIG and MC indicator highlights Micro Gaps and Micro Channels so you can track true intraday imbalances without noise. It merges
consecutive gaps, projects Fair Price Lines (FPL) that stop once touched, and offers a full intraday-ready opening-gap filter so your
early bars stay clean. The latest update refines cross-session handling, giving reliable gap plots on 1-, 5-, and 9-minute charts as well as higher time frames.
Key Features
- Detects bullish and bearish micro gaps with optional gap merging.
- Toggle opening-gap filters and configure look back, visibility, and FPL style.
- FPL lines stop as soon as price revisits the gap, making gap closure obvious.
- Micro Channel mode uses strong-close and gap filters to mark high-quality trend legs.
- Consistent behavior across intraday and higher time frames.

Volume Cluster Support and Resistance Levels [QuantAlgo]🟢 Overview
This indicator identifies statistically significant support and resistance levels through volume cluster analysis, isolating price zones characterized by elevated trading activity and institutional participation. By quantifying areas where volume concentration exceeded historical norms, it reveals price levels with demonstrated supply-demand imbalances that exhibit persistent influence on subsequent price action. The methodology is asset-agnostic and timeframe-independent, applicable across equities, cryptocurrencies, forex, and commodities from intraday to weekly intervals.
🟢 Key Features
1. Support and Resistance Levels
The indicator scans historical price data to identify bars where volume exceeds a user-defined threshold multiplier relative to the rolling average. For each qualifying bar, a representative price is calculated using the average of high, low, and close. Proximate price levels within a specified percentage range are then aggregated into discrete clusters using volume-weighted averaging, eliminating redundant signals. Clusters are ranked by cumulative volume to determine statistical significance. Finally, the indicator plots horizontal levels at each cluster price: support levels (green) below current price indicate zones where historical buying pressure exceeded selling pressure, while resistance levels (red) above current price mark zones where sellers historically dominated. These levels represent areas of established liquidity and price discovery, where institutional order flow previously concentrated.
The Touch Count (T) metric quantifies historical price interaction frequency, while Total Volume (TV) measures aggregate trading activity at each level, providing objective criteria for assessing level strength and trade execution decisions.
2. Volume Histogram
A histogram appears below the price chart, displaying relative volume for each bar within the lookback period, with bar height scaled to the maximum volume observed. Green bars represent up-periods (close > open) indicating buying pressure, while red bars show down-periods (close < open) indicating selling pressure. This visualization helps you confirm the validity of support/resistance levels by seeing where volume actually spiked, identify accumulation/distribution patterns, and validate breakouts by checking if they occur on above-average volume.
3. Built-in Alerts
Automated alerts trigger when price crosses below support levels or breaks above resistance levels, allowing you to monitor multiple assets without constant chart-watching.
4. Customizable Color Schemes
The indicator provides four preset color configurations (Classic, Aqua, Cosmic, Custom) optimized for visual clarity across different charting environments. Each scheme maintains consistent color mapping for support and resistance zones across both level lines and volume histogram components. The Custom configuration permits full color specification to accommodate individual charting setups, ensuring optimal visual contrast for extended analysis sessions.
Classic:
Aqua:
Cosmic:
Custom:
🟢 Pro Tips
→ Trade entry optimization: Execute long positions at support levels with high touch counts or upon confirmed resistance breakouts accompanied by above-average volume
→ Risk parameter definition: Position stop-loss orders near identified support/resistance zones with statistical significance to minimize premature exits
→ Breakout validation: Require volume confirmation exceeding historical average when price penetrates resistance to filter false breakouts
→ Level strength assessment: Prioritize levels with higher touch counts and total volume metrics for enhanced probability trade setups
→ Multi-timeframe confluence: Synthesize support/resistance levels across multiple timeframes to identify high-conviction zones where daily support aligns with 4-hour resistance structures


Yit BBIn this script the deviation is 1.25 the normal standard issue Bollinger band indicator uses 2. for my type of trading I don't have time price action to wait for a 2 STDRD DEV. this is a more aggressive type of indicator.
The MA is the 10 day.
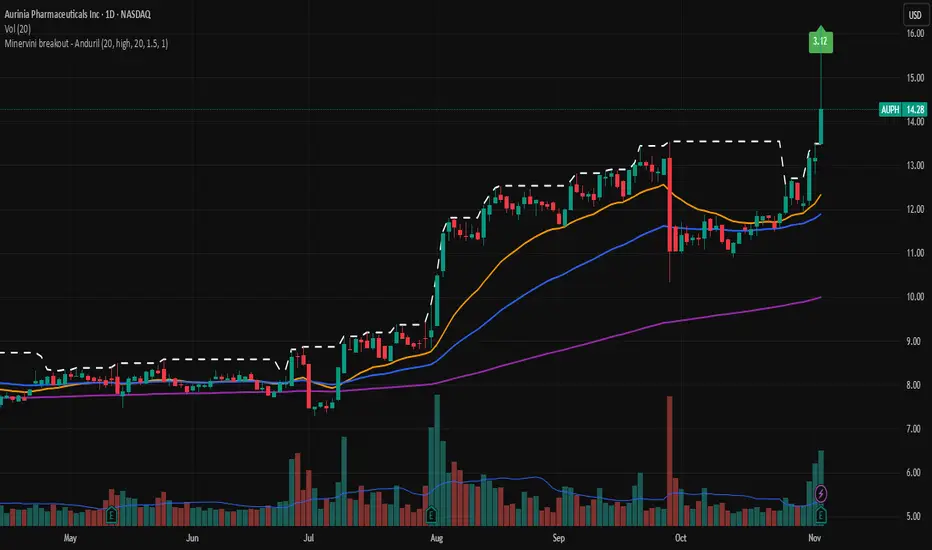
Minervini breakout - AndurilThis indicator checks the Mark Minerivini trend template as well checks consolidation areas and breakout.
Checks the highest closing price of last x days (default 20 days), exluding current day and draws a white dashed line, Calculates the relative volume of the current day. Calculates EMA 21, EMA50 and EMA200 and draws on the graph to define trend.
Gives a buy signal in green (writing relative strength of that day inside of green arrow) if:
1) Current price> breakout price* 0.98
2) Current price > EMA21 >EMA50>EMA200
3) Current price > 52 week high*0.75
4) Current price > 52 week low*1.3
5) EMA 200 of today > EMA 200 of 10 bar ago > EMA 200 of 20 bar ago
6) Relative volume of the day > 1.5
Structure Pro by MurshidfxInspired by the 'mentfx Structure' indicator created by Anton (mentfx) on TradingView,
## Overview
Structure Pro tracks market structure by maintaining an adaptive dealing range and its midpoint. Swing highs and lows become structural boundaries, and the script responds to confirmed breakouts by recalculating the active range. Labels highlight the latest trend flip so the chart stays readable while the range evolves.
## Core Logic
- Detects swing highs/lows using a configurable pivot strength and promotes confirmed pivots to structural levels.
- Applies a percentage buffer to decide when price truly breaks structure; once triggered, the opposite boundary is recalculated with an anchor search that looks back through historical bars.
- Computes equilibrium as the midpoint between the current structural high and low so you can gauge premium versus discount zones.
- Emits a single BULL or BEAR label when the trend state changes, keeping only the most recent signal on the chart.
## How to Use
1. Open a clean chart and apply only this script.
2. Select a swing strength that matches the scale you want to monitor (lower values for responsive intraday swings, higher values for broader moves).
3. Tune the structure sensitivity percentage if you prefer tighter or looser confirmation before declaring a breakout.
4. Track DRH/DRL for the current dealing range, use the equilibrium line as a mean-reversion guide, and look to the BULL/BEAR label for structure confirmation.
5. Combine the levels with your own execution, risk, and position rules—this script does not manage orders.
## Inputs
- Swing Point Strength: bars required on both sides to confirm a pivot.
- Structure Break Sensitivity: percentage buffer applied to the range before calling a breakout.
- Dealing Range display: toggles for visibility, line width/color, label text, and label size.
- Equilibrium display: line style, width, and color controls.
- Trend Signals: enable/disable labels, adjust text size, and pick label colors.
## Notes
- Designed for live structure tracking; the script relies on confirmed pivots and does not peek into future data.
- Built to be chart-agnostic for standard candles; non-standard chart types can distort the measurements.
- Published open-source so traders can review and verify the implementation details.

Breakout line - AndurilThis line shows the highest daily closing price of last 20 days default (can be adjusted from the settings). to help you to understand consolidation points and breakouts.

R Dominant Range [CRT] by Sergi SernaR Dominant Range identifies the most influential R range located to the left of the current price action. It highlights the dominant zone that still impacts market behavior, helping traders understand which range is controlling the current structure.

BB_4_in_1Bollinger Bands (4 in 1)
BB_4_in_1 is a multi-timeframe Bollinger Bands indicator that displays four different sets of Bollinger Bands on the price chart with customizable periods, line styles, and transparency levels. And just to simplify the process of applying indicators, + space saving.
Features:
- Four Bollinger Bands sets: bb_1 (20), bb_2 (80), bb_3 (160), bb_4 (320)
- Customizable period and multiplier for each set
- Unique line styles: standard, stepline, and stepline_diamond
- Adjustable line transparency for better visibility
- No fill between bands for cleaner chart layout
Ideal for multi-timeframe analysis, volatility assessment, and support/resistance level identification.

HEK Dinamik Fiyat Kanalı Stratejisi v1HEK Dynamic Price Channel Strategy
Concept
The HEK Dynamic Price Channel provides a channel structure that expands and contracts according to price momentum and time-based equilibrium.
Unlike fixed-band systems, it evaluates the interaction between price and its balance line through an adaptive channel width that dynamically adjusts to changing market conditions.
How It Works
When the price reacts to the midline, the channel bands automatically reposition themselves.
Touching the upper band indicates a strengthening trend, while touching the lower band signals weakening momentum.
This adaptive mechanism helps filter out false signals during sudden directional changes, enhancing overall signal quality.
Advantages
✅ Maintains trend continuity while avoiding overtrading.
✅ Automatically adapts to changing volatility conditions.
✅ Detects early signals of short- and mid-term trend reversals.
Applications
Directional confirmation in spot and futures markets.
A supporting tool in channel breakout strategies.
Identifying price consolidation and equilibrium zones.
Note
This strategy is intended for educational and research purposes only.
It should not be considered financial advice. Always consult a professional financial advisor before making investment decisions.
© HEK — Adaptive Channel Approach on Dynamic Market Structures
6 gün önce
Sürüm Notları
HEK Dynamic Price Channel Strategy
Concept
The HEK Dynamic Price Channel provides a channel structure that expands and contracts according to price momentum and time-based equilibrium.
Unlike fixed-band systems, it evaluates the interaction between price and its balance line through an adaptive channel width that dynamically adjusts to changing market conditions.
How It Works
When the price reacts to the midline, the channel bands automatically reposition themselves.
Touching the upper band indicates a strengthening trend, while touching the lower band signals weakening momentum.
This adaptive mechanism helps filter out false signals during sudden directional changes, enhancing overall signal quality.
Advantages
✅ Maintains trend continuity while avoiding overtrading.
✅ Automatically adapts to changing volatility conditions.
✅ Detects early signals of short- and mid-term trend reversals.
Applications
Directional confirmation in spot and futures markets.
A supporting tool in channel breakout strategies.
Identifying price consolidation and equilibrium zones.
Note
This strategy is intended for educational and research purposes only.
It should not be considered financial advice. Always consult a professional financial advisor before making investment decisions.
© HEK — Adaptive Channel Approach on Dynamic Market Structures


KeyzoneKeyzone is a dynamic support and resistance framework that identifies price reaction zones using the highest and lowest values over specific lookback periods.
It consists of four pairs of upper and lower lines:
– Keyzone 3 (light green): short-term micro swing zones
– Keyzone 8 (dark green): short-term intraday zones
– Keyzone 21 (orange): medium-term structural zones
– Keyzone 89 (red): long-term major zones
Each Keyzone adapts automatically to price movement, helping traders see where market participants are likely to react. The shorter zones (3, 8) capture quick pullbacks, while the longer zones (21, 89) reveal deeper institutional levels. This makes Keyzone a clear, multi-layered visual map of market structure that adjusts with every new candle.

KZ One — Scalping Training StrategyKZ One is a scalping strategy developed for M1 and M5 timeframes. It is designed to help traders study and practice short-term market behavior by using structured zones to highlight potential entry and exit areas. The strategy allows customization of Risk (USD) and Take Profit (R multiple) parameters for flexible trade management. Additional tools include ATR-based filters to skip low-volatility conditions and a Pre-Alert Lead (bars) option that notifies users ahead of possible setups. KZ One is intended for educational and analytical purposes, promoting disciplined and consistent trading practice.

RAFEN-G - Kill Zones & Institutional Gaps🔍 What It Does
Kill Zones (KZ1, KZ2, KZ3)
Automatically highlights the main intraday liquidity windows such as the London open, NY AM, and NY PM sessions — customizable by time, color, and transparency.
Perfect for timing setups, identifying liquidity sweeps, or backtesting session behavior.
Institutional GAP Detection (NY 11:00 → 03:00)
Anchored on the New York H1 clock, the script automatically draws the “institutional gap” between the 11:00 close and the 03:00 open of the next trading day.
Each gap is drawn as a transparent box with a label showing its size in price units.
Dynamic Cleanup & Color Updates
Automatically removes old boxes beyond your chosen history limit and keeps all visuals perfectly synchronized in real-time.
⚙️ Key Features
3 fully independent and editable Kill Zones
Adjustable timezone (default: America/New_York)
Works on all intraday timeframes
Auto-management of historical data
Clean and lightweight visuals (up to 2000 boxes)
Real-time color and transparency updates
Alerts when each Kill Zone starts
🧠 Ideal For
Traders using ICT, SMC, or institutional frameworks who want clear visual separation of market sessions and automatic tracking of session-to-session gaps for confluence or imbalance analysis.
🕐 Recommended Use
Apply on 5 min / 15 min / 1 h charts, align timezone to NYC, and combine with liquidity or FVG tools for maximum insight.

Short-Timeframe Volume Spike DetectorShort-Timeframe Volume Spike Detector
Description:
The Short-Timeframe Volume Spike Detector is an advanced multi-timeframe (MTF) indicator that automatically detects sudden volume surges and price expansion events on a lower timeframe and displays them on a higher (base) timeframe chart — helping traders identify hidden intraday accumulation or breakout pressure within broader candles.
⚙️ How It Works
Select a Base Timeframe (e.g., Daily, 4H, 1H).
The script automatically fetches data from a Lower Timeframe (e.g., Daily → 1H, 1H → 15m).
Within each base bar, it scans all the lower timeframe candles to find:
Volume Spikes: Volume exceeds average × multiplier or a custom threshold.
Price Strength: Candle shows upward movement beyond a minimum % change.
When both conditions are met, a spike signal is plotted on the higher timeframe chart.
🔍 Features
✅ Automatic Lower Timeframe Mapping — Dynamically selects the most relevant lower timeframe.
✅ Two Detection Modes:
Multiplier Mode: Volume spikes defined as multiple of average lower timeframe volume.
Manual Mode: Custom absolute volume threshold.
✅ Trend Filter Option: Show only signals during uptrends (configurable).
✅ Visual Markers:
Purple “X” = Volume Spike Detected
Dotted red & green lines = Candle range extension
✅ Custom Label Placement: Above High / Below Low / At Spike Price
✅ Debug Mode: Displays full diagnostic info including detected volume, threshold, and % change.
📊 Use Cases
Detect early accumulation in daily candles using hourly or 15-min data.
Identify institutional buying interest before visible breakouts.
Confirm strong continuation patterns after price compression.
Spot hidden intraday activity on swing or positional charts.
🧩 Inputs Overview
Input Description
Base Timeframe Main chart timeframe for analysis
Lookback Bars Number of recent candles to scan
Volume Mode “Multiplier” or “Manual Benchmark”
Volume Multiplier Multiplier applied to average lower timeframe volume
Manual Volume Threshold Fixed volume benchmark
Min Price Change % Minimum lower timeframe candle % move to qualify
Use Trend Filter Only show in uptrend (close > close )
Extend Bars Number of bars to extend dotted lines
Label Position Choose Above High / Below Low / At Spike Price
Debug Mode Show live internal values for calibration
🧠 Tips
Ideal for swing traders and multi-timeframe analysts.
Works best when base = Daily and lower = Hourly or 15m.
Combine with Volume Profile, VWAP, or RRG-style analysis for stronger confluence.
Use Multiplier 1.5–2.5 to fine-tune for your asset’s volatility.
⚠️ Notes
Works only when applied to the base timeframe selected in inputs.
May not display signals on non-standard intraday timeframes (like 3H).
Labels limited to max_labels_count for performance stability.

My Smart Volume Profile – Fixed
Title: 🔹 My Smart Volume Profile – Fixed
Description:
Lightweight custom Volume Profile showing POC, VAH, and VAL levels from recent bars. Highlights the value area, marks price touches, and supports optional alerts.
Developer Note:
Created with precision and simplicity by Magnergy

My Smart Volume Profile – Fixed
Title: 🔹 My Smart Volume Profile – Fixed
Description:
Lightweight custom Volume Profile showing POC, VAH, and VAL levels from recent bars. Highlights the value area, marks price touches, and supports optional alerts.
Developer Note:
Created with precision and simplicity by Magnergy
My Smart Volume Profile – Fixed
Title: 🔹 My Smart Volume Profile – Fixed
Description:
Lightweight custom Volume Profile showing POC, VAH, and VAL levels from recent bars. Highlights the value area, marks price touches, and supports optional alerts.
Developer Note:
Created with precision and simplicity by Magnergy


Margen de confianzaIt uses two moving averages (20 and 80). Based on their crossovers, you draw parallel bands.
The zone between these bands signals “confidence.” A downside break warns of risk; an upside break suggests price could push to new highs.
Son 2 medias moviles. Una de 20 y otra de 80. Utilizando los cruces se puede trazar lineas paralelas.
En las zonas que quedan entre estas lineas hay "confianza". Si el precio atraviesa para abajo hay peligro y si atraviesa para arriba puede ir a romper maximos
