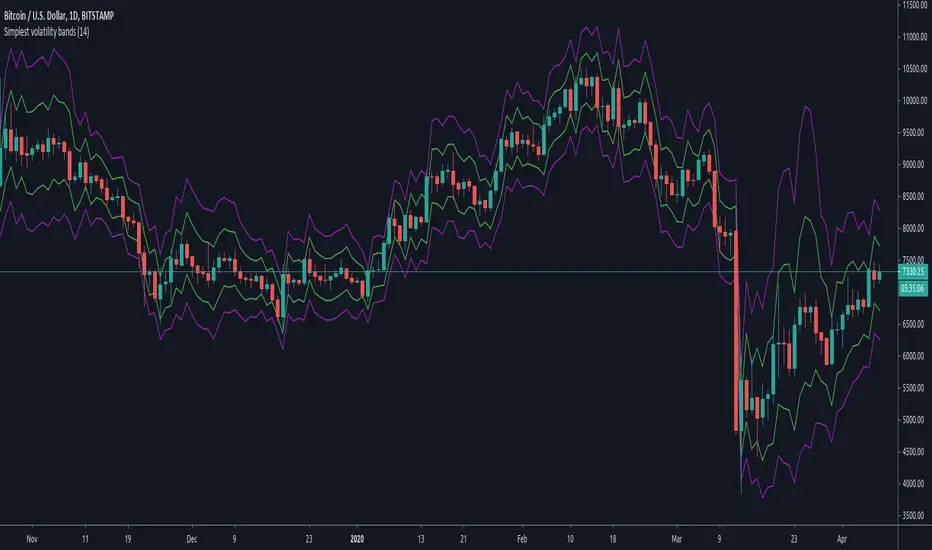
Simplest volatility bandsVolatility bands based on average candle percentage spread. Tested on BTCUSD charts only.
Based on the 68-95-99.7 rule, it seems that the spread, for daily and 4-H candles, follows a normal distribution: that means, around 85% of candles have a %-spread within sma(low/high, some_len) and sma(high/low, some_len) , and around 95% of candles within the pow2 of that range.
If you take the mean between the boundaries of the first %-spreads band, and calculate the 1.5 standard deviation of past some_len candles (I'm speaking from memory, it has been a while since I did them), the 1.5 standard deviation bands match similarly the %-spread bands, and around 85% of the candles are within these %-spread bands.
If you then take the pow2 of the bands, it will be similar to the 2 * std of the original bands, with around 95% of data within the pow2 bands.
You can take ema or other similar means with similar results, and the same for different lengths, but it seems that sma with a len of 14 is the more stable ones for both daily and 4-H, and taken other average calculations doesn't cause too many differences respect to the sma. I haven't tested too much for lower or higher timeframes.
With those %-spread bands, I multiple and divide those spreads to the open value of a new candle to get the two bands.
So, in short, you know that 85% of candles are within the closer bands, and around 95% of candles, around the bigger one. Once a new candle is born, the bands won't move (the bands are calculated from the previous candle, so the current candle's price movement doesn't move the band).
Going out the bands implies a sudden increase in volality, which usually causes rejection. They happen mostly at breakouts and ends of heavy trends. If a candle closes above the bigger band, you have probably got a breakout (a rejection rarely happens if the candle have already closed), although a breakout can happen without closing above the bands if volatility was already high.
If a trend is already stablished and is healthy, you won't probably see candles going out the bands, not even with a wick. When the trend is parabolic, and goes above the candle, the trend has probably ended, although the trend can be exhausted without going out the bands as well.
Heavy but not yet exhausted trends (specially recently started heavy downtrends), usually reach the bottom of the bigger bands during 4 o 5 contiguous candles (check visually looking at bitcoin history though, I'm speaking from memory).
So, the possibilities are multiple and you cannot use the bands to form a strategy, as usual. It can be comfortable enough psycologically for going to sleep, by moving your stop-loss to a point out of the bands in the opposite direction of your trade, and adjusting your position size accordingly; or just to check momentum looking at how close are the candle limits to the bands.
But, as usual, you are responsible of what you do with your money :)