KernelFunctionsFiltersLibrary "KernelFunctionsFilters"
This library provides filters for non-repainting kernel functions for Nadaraya-Watson estimator implementations made by @jdehorty. Filters include a smoothing formula and zero lag formula. You can find examples in the code. For more information check out the original library KernelFunctions.
rationalQuadratic(_src, _lookback, _relativeWeight, startAtBar, _filter)
Parameters:
_src (float)
_lookback (simple int)
_relativeWeight (simple float)
startAtBar (simple int)
_filter (simple string)
gaussian(_src, _lookback, startAtBar, _filter)
Parameters:
_src (float)
_lookback (simple int)
startAtBar (simple int)
_filter (simple string)
periodic(_src, _lookback, _period, startAtBar, _filter)
Parameters:
_src (float)
_lookback (simple int)
_period (simple int)
startAtBar (simple int)
_filter (simple string)
locallyPeriodic(_src, _lookback, _period, startAtBar, _filter)
Parameters:
_src (float)
_lookback (simple int)
_period (simple int)
startAtBar (simple int)
_filter (simple string)
j(line1, line2)
Parameters:
line1 (float)
line2 (float)
Regression
Ultimate Trend ChannelThe "Ultimate Trend Channel" indicator is a comprehensive trend analysis tool that calculates and displays a series of upper and lower bands based on user-defined input lengths. It uses linear regression and standard deviation to determine these bands for each of the 21 different group lengths. The indicator then computes the averages of these upper and lower bands, as well as the average of all the bands combined.
The visualization on the chart includes the plotting of the average upper and lower bands, with the space between these bands shaded for easy visualization of the overall trend. Additionally, the average of all the bands, referred to as the "Ultimate Trend Line," is also plotted on the chart.
This indicator provides a robust way of assessing market trends and volatility over varying periods, which can be extremely useful for both short-term and long-term trading strategies.

Linear Regression Channel (Log)The Linear Regression Channel (Log) indicator is a modified version of the Linear Regression channel available on TradingView. It is designed to be used on a logarithmic scale, providing a different perspective on price movements.
The indicator utilizes the concept of linear regression to visualize the overall price trend in a specific section of the chart. The central line represents the linear regression calculation, while the upper and lower lines indicate a certain number of standard deviations away from the central line. These bands serve as support and resistance levels, and when prices remain outside the channel for an extended period, a potential reversal may be anticipated.
I have replaced the Pearson values with trend strength levels to enhance understanding for individuals unfamiliar with Pearson correlation.

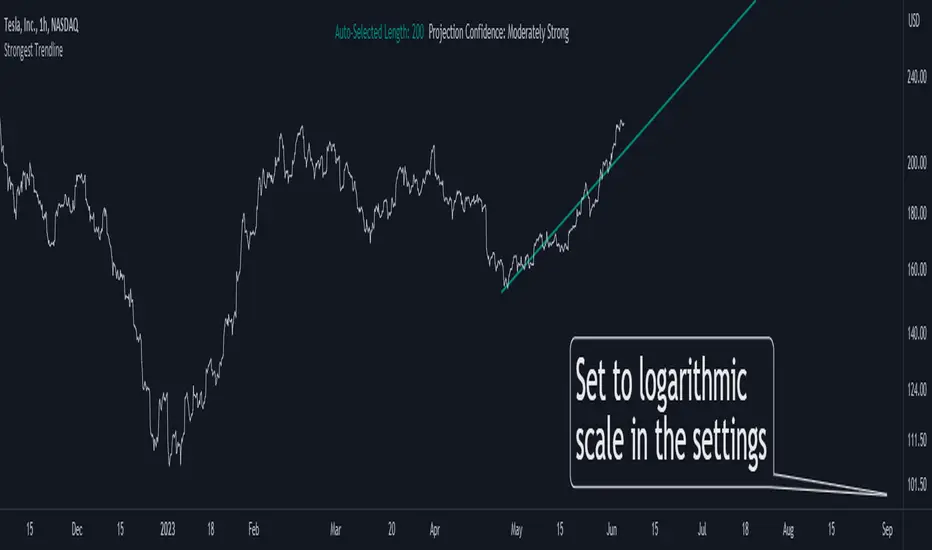
Strongest TrendlineUnleashing the Power of Trendlines with the "Strongest Trendline" Indicator.
Trendlines are an invaluable tool in technical analysis, providing traders with insights into price movements and market trends. The "Strongest Trendline" indicator offers a powerful approach to identifying robust trendlines based on various parameters and technical analysis metrics.
When using the "Strongest Trendline" indicator, it is recommended to utilize a logarithmic scale . This scale accurately represents percentage changes in price, allowing for a more comprehensive visualization of trends. Logarithmic scales highlight the proportional relationship between prices, ensuring that both large and small price movements are given due consideration.
One of the notable advantages of logarithmic scales is their ability to balance price movements on a chart. This prevents larger price changes from dominating the visual representation, providing a more balanced perspective on the overall trend. Logarithmic scales are particularly useful when analyzing assets with significant price fluctuations.
In some cases, traders may need to scroll back on the chart to view the trendlines generated by the "Strongest Trendline" indicator. By scrolling back, traders ensure they have a sufficient historical context to accurately assess the strength and reliability of the trendline. This comprehensive analysis allows for the identification of trendline patterns and correlations between historical price movements and current market conditions.
The "Strongest Trendline" indicator calculates trendlines based on historical data, requiring an adequate number of data points to identify the strongest trend. By scrolling back and considering historical patterns, traders can make more informed trading decisions and identify potential entry or exit points.
When using the "Strongest Trendline" indicator, a higher Pearson's R value signifies a stronger trendline. The closer the Pearson's R value is to 1, the more reliable and robust the trendline is considered to be.
In conclusion, the "Strongest Trendline" indicator offers traders a robust method for identifying trendlines with significant predictive power. By utilizing a logarithmic scale and considering historical data, traders can unleash the full potential of this indicator and gain valuable insights into price trends. Trendlines, when used in conjunction with other technical analysis tools, can help traders make more informed decisions in the dynamic world of financial markets.
Volume Profile Regression Channel [LuxAlgo]The Volume Profile Regression Channel calculates a volume profile from an anchored linear regression channel. Users can choose the starting and ending points for the indicator calculation interval.
Like a regular volume profile, a "line" of control (LOC), value area, and a developing LOC are displayed.
🔶 SETTINGS
Sections: The number of sections the linear regression channel is divided into for the calculation of the volume profile.
Width %: Determines the length of the profile within the channel relative to the channel length.
Value Area %: Highlights the sections starting from the POC whose accumulated volume is equal to the user-defined percentage of the total profile sections volume.
🔶 USAGES
Regular volume profiles are often constructed from a horizontal price area, this can allow highlighting price areas where most trading activity takes place.
However, when price is strongly trending a classical volume profile can sometimes be more uniform. This is where using an angled volume profile can be useful.
The line of control allows highlighting the section of the channel with the most accumulated volume, this line can be used as a potential future support/resistance. This is where an angled volume profile might be the most useful.
The developing LOC highlights the LOC location at a specific time within the profile (from left to right) and can sometimes provide an estimate of the underlying trend in the price.
🔶 DETAILS
To be computed the script requires a left and right chart time coordinates. When adding the script to their charts users can determine the left and right time coordinates by clicking on the chart.
The linear regression channel width is determined so that the channel precisely encompasses the whole price.
🔶 LIMITATIONS
Using a very large calculation interval can return timeouts. Users can reduce the calculation interval to fix that issue from occurring.
The amount of drawing objects that can be used is limited, as such using a high calculation interval can display an incomplete profile.
🔶 ACKNOWLEDGEMENTS
If you are interested in these types of scripts, @HeWhoMustNotBeNamed published a similar script where users can use a custom line angle. See his 'Angled Volume Profile' script from March 2023.

MultiMovesCombines 3 different moving averages together with the linear regression. The moving averages are the HMA, EMA, and SMA. The script makes use of two different lengths to allow the end user to utilize common crossovers in order to determine entry into a trade. The edge of each "cloud" is where each of the moving averages actually are. The bar color is the average of the shorter length combined moving averages.
-The Hull Moving Average (HMA), developed by Alan Hull, is an extremely fast and smooth moving average. In fact, the HMA almost eliminates lag altogether and manages to improve smoothing at the same time. A longer period HMA may be used to identify trend.
-The exponential moving average (EMA) is a technical chart indicator that tracks the price of an investment (like a stock or commodity) over time. The EMA is a type of weighted moving average (WMA) that gives more weighting or importance to recent price data.
-A simple moving average (SMA) is an arithmetic moving average calculated by adding recent prices and then dividing that figure by the number of time periods in the calculation average.
-The Linear Regression Indicator plots the ending value of a Linear Regression Line for a specified number of bars; showing, statistically, where the price is expected to be. Instead of plotting an average of past price action, it is plotting where a Linear Regression Line would expect the price to be, making the Linear Regression Indicator more responsive than a moving average.
The lighter colors = default 50 MA
The darker colors = default 200 MA

Advanced Trend Detection StrategyThe Advanced Trend Detection Strategy is a sophisticated trading algorithm based on the indicator "Percent Levels From Previous Close".
This strategy is based on calculating the Pearson's correlation coefficient of logarithmic-scale linear regression channels across a range of lengths from 50 to 1000. It then selects the highest value to determine the length for the channel used in the strategy, as well as for the computation of the Simple Moving Average (SMA) that is incorporated into the strategy.
In this methodology, a script is applied to an equity in which multiple length inputs are taken into consideration. For each of these lengths, the slope, average, and intercept are calculated using logarithmic values. Deviation, the Pearson's correlation coefficient, and upper and lower deviations are also computed for each length.
The strategy then selects the length with the highest Pearson's correlation coefficient. This selected length is used in the channel of the strategy and also for the calculation of the SMA. The chosen length is ultimately the one that best fits the logarithmic regression line, as indicated by the highest Pearson's correlation coefficient.
In short, this strategy leverages the power of Pearson's correlation coefficient in a logarithmic scale linear regression framework to identify optimal trend channels across a broad range of lengths, assisting traders in making more informed decisions.
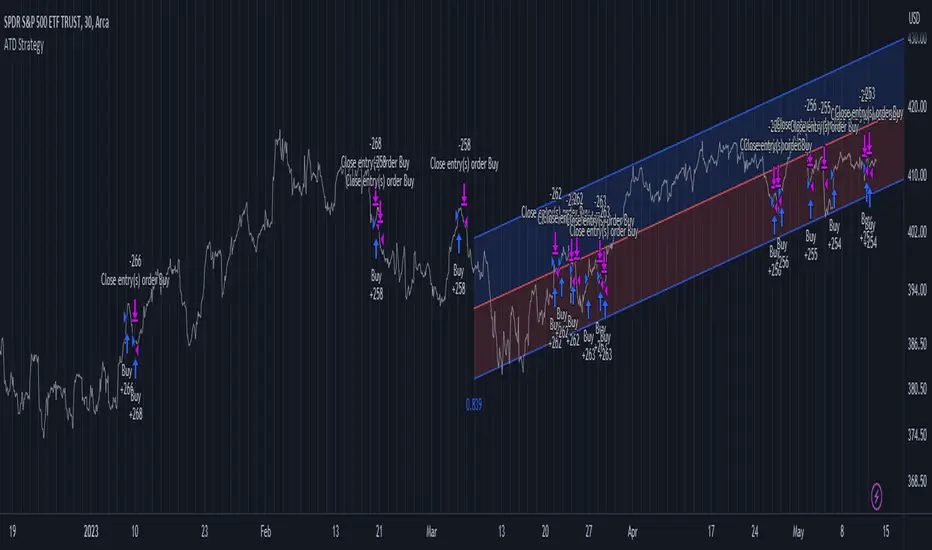
Advanced Trend Channel Detection (Log Scale)The Advanced Trend Channel Detection (Log Scale) indicator is designed to identify the strongest trend channels using logarithmic scaling. It does this by calculating the highest Pearson's R value among all length inputs and then determining which length input to use for the selected slope, average, and intercept. The script then draws the upper and lower deviation lines on the chart based on the selected slope, average, and intercept, and optionally displays the Pearson's R value.
To use this indicator, you will need to switch to logarithmic scale. There are several advantages to using logarithmic scale over regular scale. Firstly, logarithmic scale provides a better visualization of data that spans multiple orders of magnitude by compressing large ranges of values into a smaller space. Secondly, logarithmic scale can help to minimize the impact of outliers, making it easier to identify patterns and trends in the data. Finally, logarithmic scale is often utilized in scientific contexts as it can reveal relationships between variables that may not be visible on a linear scale.
If the trend channel does not appear on the chart, it may be necessary to scroll back to view historical data. The indicator uses past price data to calculate the trend channel, so if there is not enough historical data visible on the chart, the indicator may not be able to identify the trend channel. In this case, the user should adjust the chart's timeframe or zoom out to view more historical data. Additionally, the indicator may need to be recalibrated if there is a significant shift in market conditions or if the selected length input is no longer appropriate.
MACD TrueLevel StrategyThis strategy uses the MACD indicator to determine buy and sell signals. In addition, the strategy employs the use of "TrueLevel Bands," which are essentially envelope bands that are calculated based on the linear regression and standard deviation of the price data over various lengths.
The TrueLevel Bands are calculated for 14 different lengths and are plotted on the chart as lines. The bands are filled with a specified color to make them more visible. The highest upper band and lowest lower band values are stored in variables for easy access.
The user can input the lengths for the TrueLevel Bands and adjust the multiplier for the standard deviation. They can also select the bands they want to use for entry and exit, and enable long and short positions.
The entry conditions for a long position are either a crossover of the MACD line over the signal line or a crossover of the price over the selected entry lower band. The entry conditions for a short position are either a crossunder of the MACD line under the signal line or a crossunder of the price under the selected exit upper band.
The exit conditions for both long and short positions are not specified in the code and are left to the user to define.
Overall, the strategy aims to capture trends by entering long or short positions based on the MACD and TrueLevel Bands, and exiting those positions when the trend reverses.
Deming Linear Regression [wbburgin]Deming regression is a type of linear regression used to model the relationship between two variables when there is variability in both variables. Deming regression provides a solution by simultaneously accounting for the variability in both the independent and dependent variables, resulting in a more accurate estimation of the underlying relationship. In the hard-science fields, where measurements are critically important to judging the conclusions drawn from data, Deming regression can be used to account for measurement error.
Tradingview's default linear regression indicator (the ta.linreg() function) uses least squares linear regression, which is similar but different than Deming regression. In least squares regression, the regression function minimizes the sum of the squared vertical distances between the data points and the fitted line. This method assumes that the errors or variability are only present in the y-values (dependent variable), and that the x-values (independent variable) are measured without error.
In time series data used in trading, Deming regression can be more accurate than least squares regression because the ratio of the variances of the x and y variables is large. X is the bar index, which is an incrementally-increasing function that has little variance, while Y is the price data, which has extremely high variance when compared to the bar index. In such situations, least squares regression can be heavily influenced by outliers or extreme points in the data, whereas Deming regression is more resistant to such influence.
Additionally, if your x-axis uses variable widths - such as renko blocks or other types of non-linear widths - Deming regression might be more effective than least-squares linear regression because it accounts for the variability in your x-values as well. Additionally, if you are creating a machine-learning model that uses linear regression to filter or extrapolate data, this regression method may be more accurate than least squares.
In contrast to least squares regression, Deming regression takes into account the variability or errors in both the x- and y-values. It minimizes the sum of the squared perpendicular distances between the data points and the fitted line, accounting for both the x- and y-variability. This makes Deming regression more robust in both variables than least squares regression.

RSI TrueLevel StrategyThis strategy is a momentum-based strategy that uses the Relative Strength Index (RSI) indicator and a TrueLevel envelope to generate trade signals.
The strategy uses user-defined input parameters to calculate TrueLevel envelopes for 14 different lengths. The TrueLevel envelope is a volatility-based technical indicator that consists of upper and lower bands. The upper band is calculated by adding a multiple of the standard deviation to a linear regression line of the price data, while the lower band is calculated by subtracting a multiple of the standard deviation from the same regression line.
The strategy generates long signals when the RSI crosses above the oversold level or when the price crosses above the selected lower band of the TrueLevel envelope. It generates short signals when the RSI crosses below the overbought level or when the price crosses below the selected upper band of the TrueLevel envelope.
The strategy allows for long and short trades and sets the trade size as a percentage of the account equity. The colors of the bands and fills are also customizable through user-defined input parameters.
In this strategy, the 12th TrueLevel band was chosen due to its ability to capture significant price movements while still providing a reasonable level of noise reduction. The strategy utilizes a total of 14 TrueLevel bands, each with varying lengths. The 12th band, with a length of 2646, strikes a balance between sensitivity to market changes and reducing false signals, making it a suitable choice for this strategy.
RSI Parameters:
In this strategy, the RSI overbought and oversold levels are set at 65 and 40, respectively. These values were chosen to filter out more noise in the market and focus on stronger trends. Traditional RSI overbought and oversold levels are set at 70 and 30, respectively. By raising the oversold level and lowering the overbought level, the strategy aims to identify more significant trend reversals and potential trade opportunities.
Of course, the parameters can be adjusted to suit individual preferences.

Chandelier Exit ZLSMA StrategyIntroducing a Powerful Trading Indicator: Chandelier Exit with ZLSMA
If you're a trader, you know the importance of having the right tools and indicators to make informed decisions. That's why we're excited to introduce a powerful new trading indicator that combines the Chandelier Exit and ZLSMA: two widely-used and effective indicators for technical analysis.
The Chandelier Exit (CE) is a popular trailing stop-loss indicator developed by Chuck LeBeau. It's designed to follow the price trend of a security and provide an exit signal when the price crosses below the CE line. The CE line is based on the Average True Range (ATR), which is a measure of volatility. This means that the CE line adjusts to the volatility of the security, making it a reliable indicator for trailing stop-losses.
The ZLEMA (Zero Lag Exponential Moving Average) is a type of exponential moving average that's designed to reduce lag and improve signal accuracy. The ZLSMA takes into account not only the current price but also past prices, using a weighted formula to calculate the moving average. This makes it a smoother indicator than traditional moving averages, and less prone to giving false signals.
When combined, the CE and ZLSMA create a powerful indicator that can help traders identify trend changes and make more informed trading decisions. The CE provides the trailing stop-loss signal, while the ZLSMA provides a smoother trend line to help identify potential entry and exit points.
In our indicator, the CE and ZLSMA are plotted together on the chart, making it easy to see both the trailing stop-loss and the trend line at the same time. The CE line is displayed as a dotted line, while the ZLSMA line is displayed as a solid line.
Using this indicator, traders can set their stop-loss levels based on the CE line, while also using the ZLSMA line to identify potential entry and exit points. The combination of these two indicators can help traders reduce their risk and improve their trading performance.
In conclusion, the Chandelier Exit with ZLSMA is a powerful trading indicator that combines two effective technical analysis tools. By using this indicator, traders can identify trend changes, set stop-loss levels, and make more informed trading decisions. Try it out for yourself and see how it can improve your trading performance.
Warning: The results in the backtest are from a repainting strategy. Don't take them seriously. You need to do a dry live test in order to test it for its useability.
-
Here is a description of each input field in the provided source code:
length: An integer input used as the period for the ATR (Average True Range) calculation. Default value is 1.
mult: A float input used as a multiplier for the ATR value. Default value is 2.
showLabels: A boolean input that determines whether to display buy/sell labels on the chart. Default value is false.
isSignalLabelEnabled: A boolean input that determines whether to display signal labels on the chart. Default value is true.
useClose: A boolean input that determines whether to use the close price for extrema calculations. Default value is true.
zcolorchange: A boolean input that determines whether to enable rising/decreasing highlighting for the ZLSMA (Zero-Lag Exponential Moving Average) line. Default value is false.
zlsmaLength: An integer input used as the length for the ZLSMA calculation. Default value is 50.
offset: An integer input used as an offset for the ZLSMA calculation. Default value is 0.
-
Ty for checking this out and good luck on your trading journey! Likes and comments are appreciated. 👍
--
Credits to:
▪ @everget – Chandelier Exit (CE)
▪ @netweaver2022 – ZLSMA

Trend forecasting by c00l75----------- ITALIANO -----------
Questo codice è uno script di previsione del trend creato solo a scopo didattico. Utilizza una media mobile esponenziale (EMA) e una media mobile di Hull (HMA) per calcolare il trend attuale e prevedere il trend futuro. Il codice utilizza anche una regressione lineare per calcolare il trend attuale e un fattore di smorzamento per regolare l’effetto della regressione lineare sulla previsione del trend. Infine il codice disegna due linee tratteggiate per mostrare la previsione del trend per i periodi futuri specificati dall’utente. Se ti piace l'idea mettimi un boost e lascia un commento!
----------- ENGLISH -----------
This code is a trend forecasting script created for educational purposes only. It uses an exponential moving average (EMA) and a Hull moving average (HMA) to calculate the current trend and forecast the future trend. The code also uses a linear regression to calculate the current trend and a damping factor to adjust the effect of the linear regression on the trend prediction. Finally, the code draws two dashed lines to show the trend prediction for future periods specified by the user. If you like the idea please put a boost and leave a comment!
Regression Channel Alternative MTF V2█ OVERVIEW
This indicator is a predecessor to Regression Channel Alternative MTF , which is coded based on latest update of type, object and method.
█ IMPORTANT NOTES
This indicator is NOT true Multi Timeframe (MTF) but considered as Alternative MTF which calculate 100 bars for Primary MTF, can be refer from provided line helper.
The timeframe scenarios are defined based on Position, Swing and Intraday Trader.
Suppported Timeframe : W, D, 60, 15, 5 and 1.
Channel drawn based on regression calculation.
Angle channel is NOT supported.
█ INSPIRATIONS
These timeframe scenarios are defined based on Harmonic Trading : Volume Three written by Scott M Carney.
By applying channel on each timeframe, MW or ABCD patterns can be easily identified manually.
This can also be applied on other chart patterns.
█ CREDITS
Scott M Carney, Harmonic Trading : Volume Three (Reaction vs. Reversal)
█ TIMEFRAME EXPLAINED
Higher / Distal : The (next) longer or larger comparative timeframe after primary pattern has been identified.
Primary / Clear : Timeframe that possess the clearest pattern structure.
Lower / Proximate : The (next) shorter timeframe after primary pattern has been identified.
Lowest : Check primary timeframe as main reference.
█ FEATURES
Color is determined by trend or timeframe.
Some color is depends on chart contrast color.
Color is determined by trend or timeframe.
█ EXAMPLE OF USAGE / EXPLAINATION

Autoregressive Covariance Oscillator by TenozenWell to be honest I don't know what to name this indicator lol. But anyway, here is my another original work! Gonna give some background of why I create this indicator, it's all pretty much a coincidence when I'm learning about time series analysis.
_ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _
Well, the formula of Auto-covariance is:
E{(X(t)-(t) * (X(t-s)-(t-s))}= Y_s
But I don't multiply both values but rather subtract them:
E{(X(t)-(t) - (X(t-s)-(t-s))}= Y_s?
_ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _
For arm_vald, the equation is as follows:
arm_vald = val_mu + mu_plus_lsm + et
val_mu --> mean of time series
mu_plus_lsm --> val_mu + LSM
et --> error term
As you can see, val_mu^2. I did this so the oscillator is much smoother.
_ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _
After I get the value, I normalize them:
aco = Y_s? / arm_vald
So by this calculation, I get something like an oscillator!
(more details in the code)
_ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _
So how to use this indicator? It's so easy! If the value is above 0, we gonna expect a bullish response, if the value is below 0, we gonna expect a bearish response; that simple. Be aware that you should wait for the price to be closed before executing a trade.
Well, try it out! So far this is the most powerful indicator that I've created, hope it's useful. Ciao.
(more updates for the indicator if needed)

Linear Regression Volume ProfileLinear Regression Volume Profile plots the volume profile fixated on the linear regression of the lookback period rather than statically across y = 0. This helps identify potential support and resistance inside of the price channel.
Settings
Linear Regression
Linear Regression Source: the price source in which to sample when calculating the linear regression
Length: the number of bars to sample when calculating the linear regression
Deviation: the number of standard deviations away from the linear regression line to draw the upper and lower bounds
Linear Regression
Rows: the number of rows to divide the linear regression channel into when calculating the volume profile
Show Point of Control: toggle whether or not to plot the level with highest amount of volume
Usage
Similar to the traditional Linear Regression and Volume Profile this indicator is mainly to determine levels of support and resistance. One may interpret a level with high volume (i.e. point of control) to be a potential reversal point.
Details
This indicator first calculates the linear regression of the specified lookback period and, subsequently, the upper and lower bound of the linear regression channel. It then divides this channel by the specified number of rows and sums the volume that occurs in each row. The volume profile is scaled to the min and max volume.
Linear Regress on Price And VolumeLinear regression is a statistical method used to model the relationship between a dependent variable and one or more independent variables. It assumes a linear relationship between the dependent variable and the independent variable(s) and attempts to fit a straight line that best describes the relationship.
In the context of predicting the price of a stock based on the volume, we can use linear regression to build a model that relates the price of the stock (dependent variable) to the volume (independent variable). The idea is to use lookback period to predict future prices based on the volume.
To build this indicator, we start by collecting data on the price of the stock and the volume over a selected of time or by default 21 days. We then plot the data on a scatter plot with the volume on the x-axis and the price on the y-axis. If there is a clear pattern in the data, we can fit a straight line to the data using a method called least squares regression. The line represents the best linear approximation of the relationship between the price and the volume.
Once we have the line, we can use it to make predictions. For example, if we observe a certain volume, we can use the line to estimate the corresponding price.
It's worth noting that linear regression assumes a linear relationship between the variables. In reality, the relationship between the price and the volume may be more complex, and other factors may also influence the price of the stock. Therefore, while linear regression can be a useful tool, it should be used in conjunction with other methods and should be interpreted with caution.
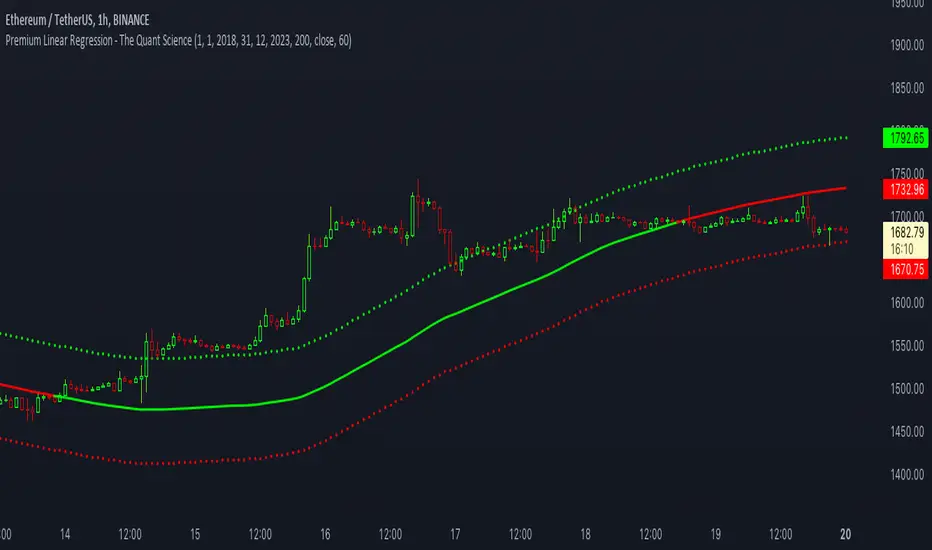
Premium Linear Regression - The Quant ScienceThis script calculates the average deviation of the source data from the linear regression. When used with the indicator, it can plot the data line and display various pieces of information, including the maximum average dispersion around the linear regression.
The code includes various user configurations, allowing for the specification of the start and end dates of the period for which to calculate linear regression, the length of the period to use for the calculation, and the data source to use.
The indicator is designed for multi-timeframe use and to facilitate analysis for traders who use regression models in their analysis. It displays a green linear regression line when the price is above the line and a red line when the price is below. The indicator also highlights areas of dispersion around the regression using circles, with bullish areas shown in green and bearish areas shown in red.
VHF Adaptive Linear Regression KAMAIntroduction
Heyo, in this indicator I decided to add VHF adaptivness, linear regression and smoothing to a KAMA in order to squeeze all out of it.
KAMA:
Developed by Perry Kaufman, Kaufman's Adaptive Moving Average (KAMA) is a moving average designed to account for market noise or volatility. KAMA will closely follow prices when the price swings are relatively small and the noise is low. KAMA will adjust when the price swings widen and follow prices from a greater distance. This trend-following indicator can be used to identify the overall trend, time turning points and filter price movements.
VHF:
Vertical Horizontal Filter (VHF) was created by Adam White to identify trending and ranging markets. VHF measures the level of trend activity, similar to ADX DI. Vertical Horizontal Filter does not, itself, generate trading signals, but determines whether signals are taken from trend or momentum indicators. Using this trend information, one is then able to derive an average cycle length.
Linear Regression Curve:
A line that best fits the prices specified over a user-defined time period.
This is very good to eliminate bad crosses of KAMA and the pric.
Usage
You can use this indicator on every timeframe I think. I mostly tested it on 1 min, 5 min and 15 min.
Signals
Enter Long -> crossover(close, kama) and crossover(kama, kama )
Enter Short -> crossunder(close, kama) and crossunder(kama, kama )
Thanks for checking this out!
--
Credits to
▪️@cheatcountry – Hann Window Smoohing
▪️@loxx – VHF and T3
▪️@LucF – Gradient
Dynamic Linear Regression Oscillator | AdulariDescription:
This dynamic linear regression oscillator visualizes the general price trend of specific ranges in the chart based on the linear regression calculation, it automatically determines these ranges with pivot detection. The central line of the indicator is the baseline of the linear regression itself. This is a good tool to use to determine when a price is unusually far away from its baseline. The lines above or below it are overbought and oversold zones. These zones are based on the high or low of the range, in combination with the set multipliers.
The overbought and oversold lines indicate support and resistance; when the prices stay outside these levels for a significant period of time, a reversal can be expected soon. When the oscillator's value crosses above the signal or smoothed line the trend may become bullish. When it crosses below, the trend may become bearish.
This indicator is quite special, as it first determines price ranges using pivot detection. It then uses the middle of the range to determine how far the current price is from the baseline. This value is then rescaled compared to a set amount of bars back, putting it into relevant proportions with the current price action.
How do I use it?
Never use this indicator as standalone trading signal, it should be used as confluence.
When the value crosses above the signal this indicates the current bearish trend is getting weak and may reverse upwards.
When the value crosses below the signal this indicates the current bullish trend is getting weak and may reverse downwards.
When the value is above the middle line this shows the bullish trend is strong.
When the value is below the middle line this shows the bearish trend is strong.
When the value crosses above the upper line this indicates the trend may reverse downwards.
When the value crosses below the lower line this indicates the trend may reverse upwards.
Features:
Oscillator value indicating how far the price has currently deviated from the middle of the range. Proportioned to data from a set amount of bars ago.
Signal value to indicate whether or not the price is abnormally far from the middle of the range.
Horizontal lines such as oversold, overbought and middle lines, indicating possible reversal zones.
Automatic range detection using pivots.
Built-in rescaling functionality to ensure values are proportionate with the latest data.
How does it work? (simplified)
1 — Calculate the middle of the range.
2 — Define whether the current price is above the middle of the range or below.
3 — If above the middle of the range, calculate the difference of the current high and the middle line. If below, calculate the difference of the current low and the middle line.
4 — Smooth the value using a set moving average type.
5 — Rescale the value to proportionate it with the latest data.

Nadaraya-Watson: Envelope (Non-Repainting)Due to popular request, this is an envelope implementation of my non-repainting Nadaraya-Watson indicator using the Rational Quadratic Kernel. For more information on this implementation, please refer to the original indicator located here:
What is an Envelope?
In technical analysis, an "envelope" typically refers to a pair of upper and lower bounds that surrounds price action to help characterize extreme overbought and oversold conditions. Envelopes are often derived from a simple moving average (SMA) and are placed at a predefined distance above and below the SMA from which they were generated. However, envelopes do not necessarily need to be derived from a moving average; they can be derived from any estimator, including a kernel estimator such as Nadaraya-Watson.
How to use this indicator?
Overall, this indicator offers a high degree of flexibility, and the location of the envelope's bands can be adjusted by (1) tweaking the parameters for the Rational Quadratic Kernel and (2) adjusting the lookback window for the custom ATR calculation. In a trending market, it is often helpful to use the Nadaraya-Watson estimate line as a floating SR and/or reversal zone. In a ranging market, it is often more convenient to use the two Upper Bands and two Lower Bands as reversal zones.
How are the Upper and Lower bounds calculated?
In this indicator, the Rational Quadratic (RQ) Kernel estimates the price value at each bar in a user-defined lookback window. From this estimation, the upper and lower bounds of the envelope are calculated based on a custom ATR calculated from the kernel estimations for the high, low, and close series, respectively. These calculations are then scaled against a user-defined multiplier, which can be used to further customize the Upper and Lower bounds for a given chart.
How to use Kernel Estimations like this for other indicators?
Kernel Functions are highly underrated, and when calibrated correctly, they have the potential to provide more value than any mundane moving average. For those interested in using non-repainting Kernel Estimations for technical analysis, I have written a Kernel Functions library that makes it easy to access various well-known kernel functions quickly. The Rational Quadratic Kernel is used in this implementation, but one can conveniently swap out other kernels from the library by modifying only a single line of code. For more details and usage examples, please refer to the Kernel Functions library located here:

Regression Fit Bollinger Bands [Spiritualhealer117]This indicator is best suited for mean reversion trading, shorting at the upper band and buying at the lower band, but it can be used in all the same ways as a standard bollinger band.
It differs from a normal bollinger band because it is centered around the linear regression line, as opposed to the moving average line, and uses the linear regression of the standard deviation as opposed to the standard deviation.
This script was an experiment with the new vertical gradient fill feature.

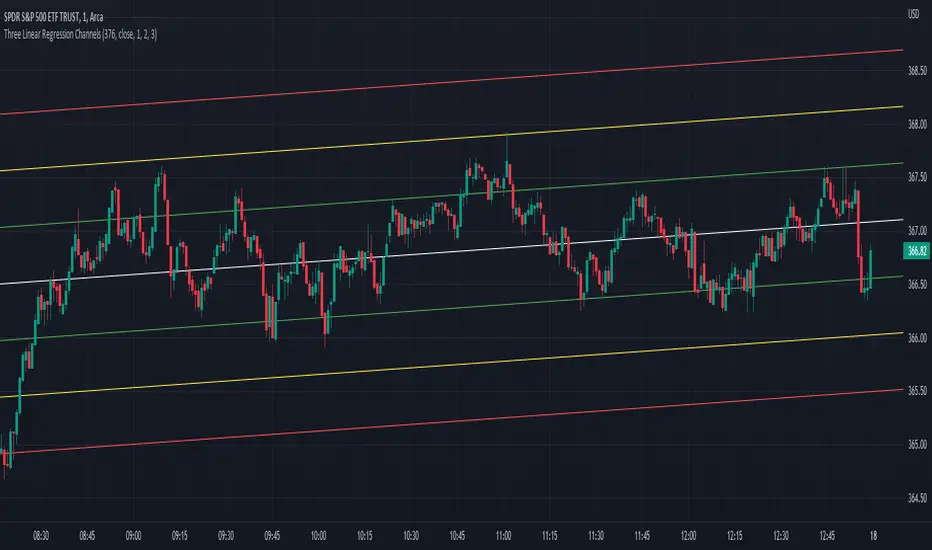
Three Linear Regression ChannelsPlot three linear regression channels using alexgrover 's Computing The Linear Regression Using The WMA And SMA indicator for the linear regression calculations.
Settings
Length : Number of inputs to be used
Source : Source input of the indicator
Midline Colour : The colour of the midline
Channel One, Two, and Three Multiplicative Factor : Multiplication factor for the RMSE, determine the distance between the upper and lower level
Channel One, Two, and Three Colour : The channel's lines colour
Usage
For usage details, please refer to alexgrover 's Computing The Linear Regression Using The WMA And SMA indicator.