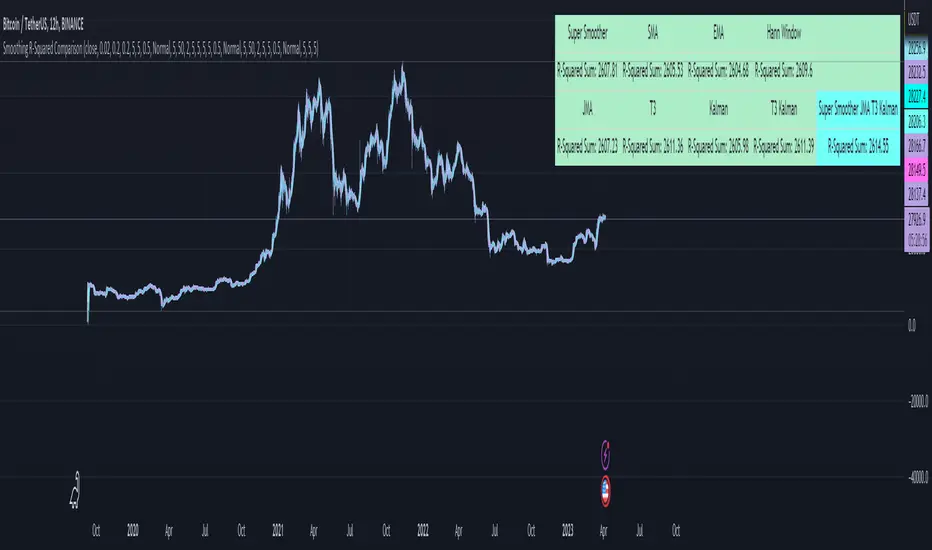
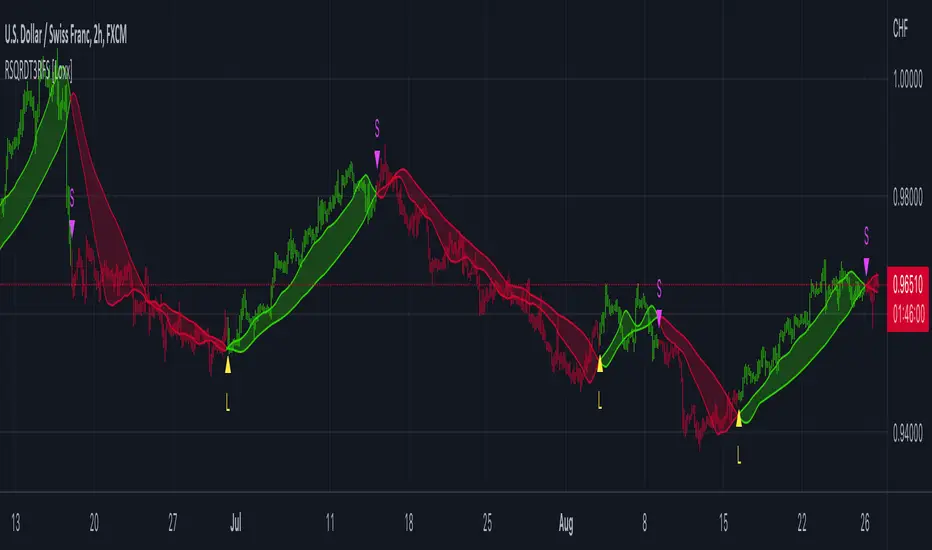
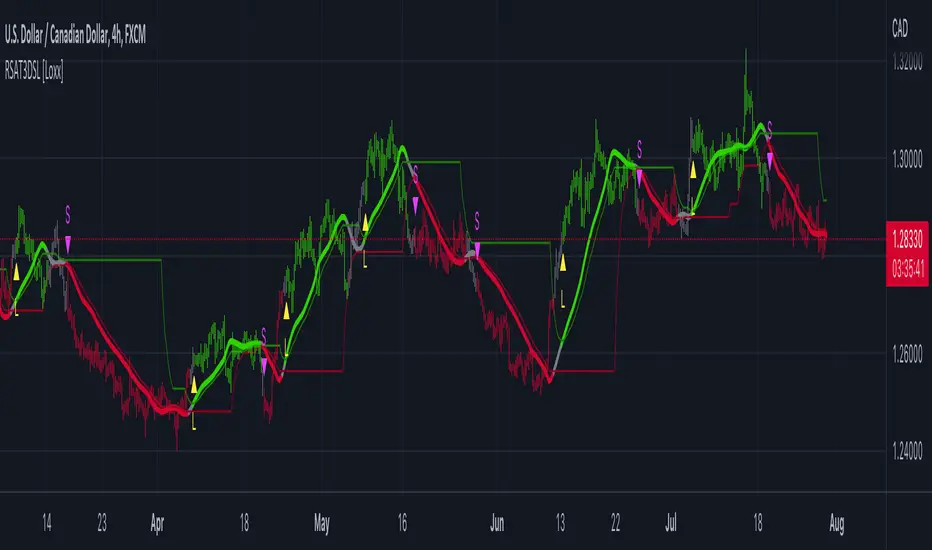
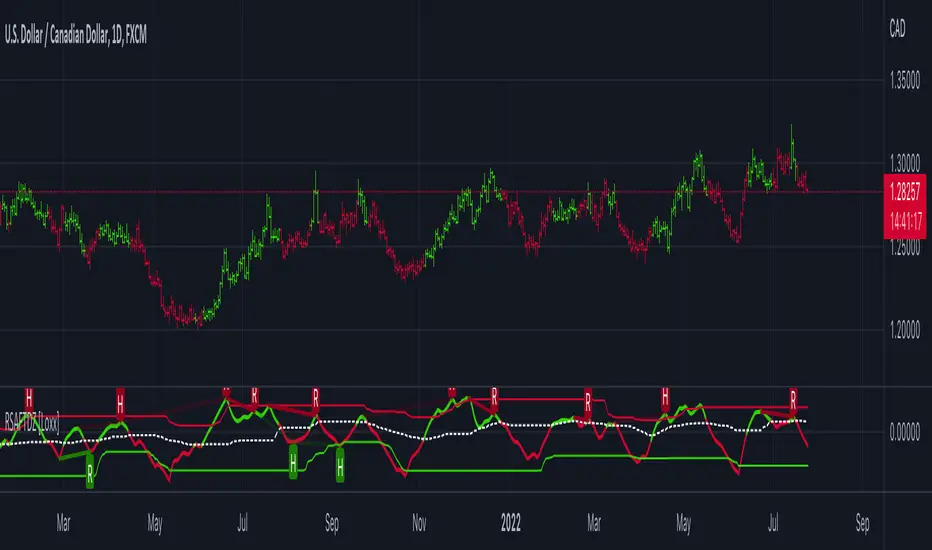
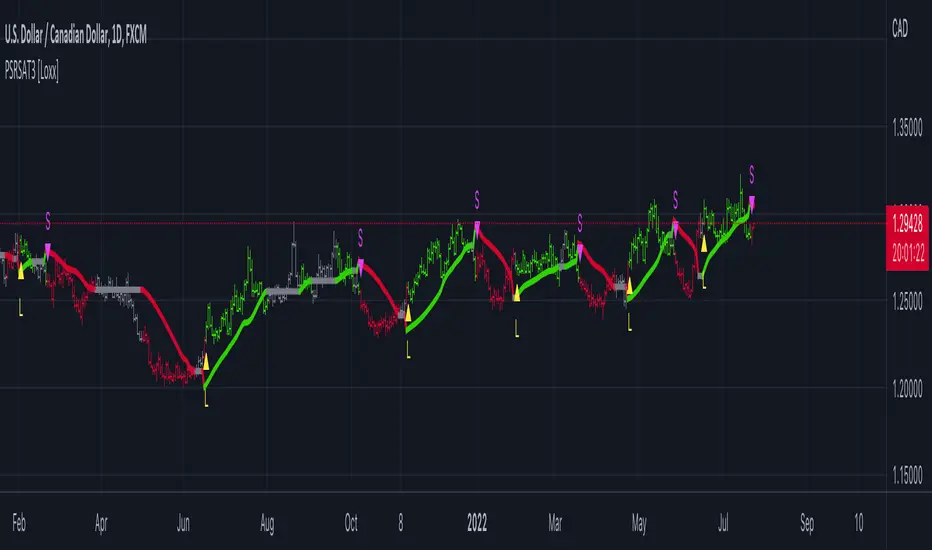
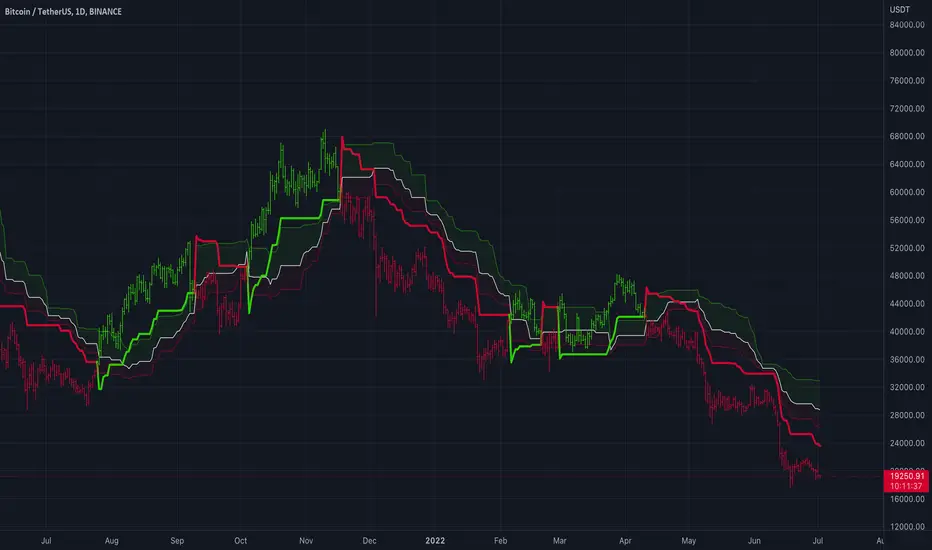
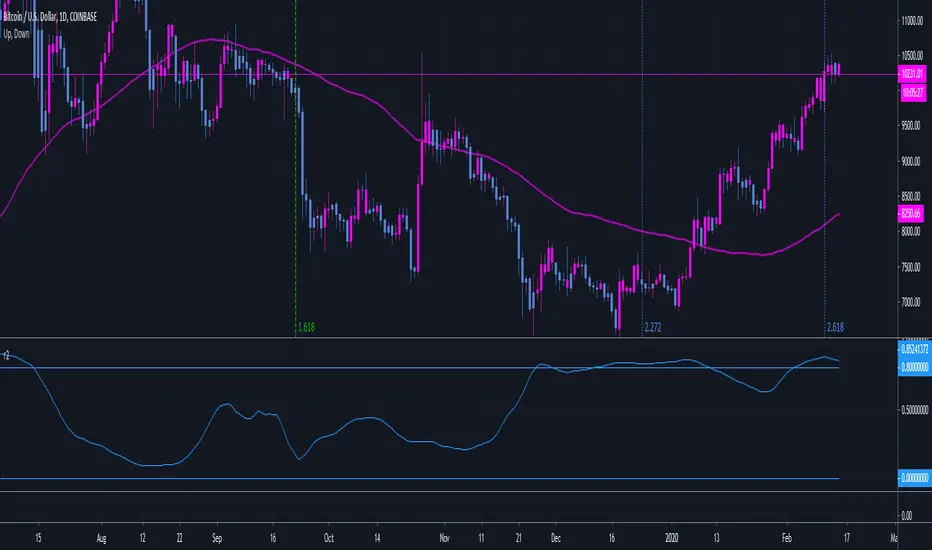
RSquared (log prices)Rolling Trend R² measures the strength of trends using a rolling R² calculation on log prices. Values near 1 indicate a strong, persistent trend, while low values signal choppy or mean-reverting conditions. Includes regime highlighting, reference levels, and an info panel for quick market state identification.
Indicateur Pine Script®