Risk Reward Calculator [lovealgotrading]
OVERVIEW:
This Risk Reward Calculator strategy can help you maximize your RR value with help of algorithmic trading.
INDICATOR:
I wanted to setup my trades more easier with this indicator, I didn't want to calculate everytime before orders, with help this indicator we can calculate R:R value, avarage price, stoploss price, take-profit price, order prices, all position cost and more ...
Our strategy is a risk revard calculation indicator that is made easy to use by using visualized lines and panels, and also has algorithmic trading support.
With the help of this indicator, we can quickly and easily calculate our risk reward values and enter the positions.
If we want to ensure that our balance grows regularly while trading in the stock market, we need to manage the risks and rewards otherwise we may fall below our initial balance at the end of the day, even if we seem to be winning.
What is the Risk-Reward value ?
This value is a value that shows how many times the amount of risk we take when entering the position is successful, we will earn.
- For example, you risked $100 while entering the trade, so if your trade stops, you will lose 100 $.
Your Risk-Reward(RR) value is 2 means that if your position is successful, you will have 200 $ in your pocket.
A trader's success is determined by the amount of R he earns monthly or yearly, not how much money he makes.
What is different in this indicator ?
I want to say thank you to © EvoCrypto. His Calculator (weighted) – evo indicator helped me when I was developed my indicator.
I want to explain what I have improved:
1-In this strategy, we can determine the time period in which we want to open our positions.
2-We can open a maximum of 4 positions in the same direction and close our positions at a single level. StopLoss or TakeProfit
3-This indicator, which works in the form of a strategy, shows where our positions have been opened or closed. With the help of this, it helps us to determine our strategy in our future positions more accurately.
4-The most important improvement is that we do not miss our positions with the help of alarms (WEB HOOK). if we want, we receive by quickly connecting all these positions to our robot, the software can enter and exit the position while we are busy.
IMPLEMENTATION DETAILS – SETTINGS:
1 - We can set the start and end dates of the positions we will take.
2- We can set our take profit, stoploss levels.
3- If your trade is stopped, we can determine the amount of the trade that we will lose.
4- We can adjust our entry levels to positions and our position sizes at entry levels.
(Sum of positions weight must be 100%)
5- We can receive our positions even if we are busy with the help of algorithmic trading. For this, we must paste our Jshon codes into the fields specified in the settings panel.
6- Finally, we can change the settings we want and don't want to have in our visual elements.
Let's make a LONG side example together
We have determined our positions to enter stoploss, take profit and long positions. We did not forget to set the start time of our strategy
Our strategy appear on the graph as follows.
Our strategy has calculated the total position size, our R-R value, the distance of the current price to the stop and take profit levels, in short, a lot of things we could look visually.
Notes:
If you're going to connect this bot to an automatic Long or Short direction,
Don’t forget! you need to Webhook URL,
Don’t miss paste this code to your message window {{strategy.order.alert_message}}
ALSO:
If you have any ideas what to add to my work to add more sources or make calculations cooler, feel free to write me.
Recherche dans les scripts pour "algo"

iMoku (Ichimoku Complete Tool) - The Quant Science iMoku™ is a professional all-in-one solution for the famous Ichimoku Kinko Hyo indicator.
The algorithm includes:
1. Backtesting spot
2. Visual tool
3. Auto-trading functions
With iMoku you can test four different strategies.
Strategy 1: Cross Tenkan Sen - Kijun Sen
A long position is opened with 100% of the invested capital ($1000) when "Tenkan Sen" crossover "Kijun Sen".
Closing the long position on the opposite condition.
There are 3 different strength signals for this strategy: weak, normal, strong.
Weak : the signal is weak when the condition is true and the price is above the 'Kumo'
Normal : the signal is normal when the condition is true and the price is within the 'Kumo'
Strong : the signal is strong when the condition is true and the price is below the 'Kumo'
Strategy 2: Cross Price - Kijun Sen
A long position is opened with 100% of the invested capital ($1000) when the price crossover the 'Kijun Sen'.
Closing the long position on the opposite condition.
There are 3 different strength signals for this strategy: weak, normal, strong.
Weak : the signal is weak when the condition is true and the price is above the 'Kumo'
Normal : the signal is normal when the condition is true and the price is inside the 'Kumo'
Strong : the signal is strong when the condition is true and the price is below the 'Kumo'
Strategy 3: Kumo Breakout
A long position is opened with 100% of the invested capital ($1000) when the price breakup the 'Kumo'.
Closing the long position with a percentage stop loss and take profit on the invested capital.
Strategy 4: Kumo Twist
A long position is opened with 100% of the invested capital ($1000) when the 'Kumo' goes from negative to positive (called "Twist").
Closing the long position on the opposite condition.
There are 2 different strength signals for this strategy: weak, and strong.
Weak : the signal is weak when the condition is true and the price is above the 'Kumo'
Strong : the signal is strong when the condition is true and the price is below the 'Kumo'
This script is compliant with algorithmic trading.
You can use this script with trading terminals such as 3Commas or CryptoHopper. Connecting this script is very easy.
1. Enter the user interface
2. Select and activate a strategy
3. Copy your bot's links into the dedicated fields
4. Create and activate alert
Disclaimer: algorithmic trading involves risk, the user should consider aspects such as slippage, liquidity and costs when evaluating an asset. The Quant Science is not responsible for any kind of damage resulting from use of this script. By using this script you take all the responsibilities and risks.

Apex Edge – Wolfe Wave HunterApex Edge – Wolfe Wave Hunter
The modern Wolfe Wave, rebuilt for the algo era
This isn’t just another Wolfe Wave indicator. Classic Wolfe detection is rigid, outdated, and rarely tradable. Apex Edge – Wolfe Wave Hunter re-engineers the pattern into a modern, SMC-driven model that adapts to today’s liquidity-dominated markets. It’s not about drawing pretty shapes – it’s about extracting precision entries with asymmetric risk-to-reward potential.
🔎 What it does
Automatic Wolfe Wave Detection
Identifies bullish and bearish Wolfe Wave structures using pivot-based logic, symmetry filters, and slope tolerances.
Channel Glow Zones
Highlights the Wolfe channel and projects it forward into the future (bars are user-defined). This allows you to see the full potential of the trade before price even begins its move.
Stop Loss (SL) & Entry Arrow
At the completion of Wave 5, the algo prints a Stop Loss line and a tiny entry arrow (green for bullish, red for bearish). but the colours can be changed in user settings. This is the “execution point” — where the Wolfe setup becomes tradable.
Target Projection Lines
TP1 (EPA): Derived from the traditional 1–4 line projection.
TP2 (1.272 Fib): Optional secondary profit target.
TP3 (1.618 Fib): Optional extended target for large runners.
All TP lines extend into the future, so you can track them as price evolves.
Volume Confirmation (optional)
A relative volume filter ensures Wave 5 is formed with meaningful market participation before a setup is confirmed.
Alerts (ready out of the box)
Custom alerts can be fired whenever a bullish or bearish Wolfe Wave is confirmed. No need to babysit the charts — let the script notify you.
⚙️ Customisation & User Control
Every trader’s market and style is different. That’s why Wolfe Wave Hunter is fully customisable:
Arrow Colours & Size
Works on both light and dark charts. Choose your own bullish/bearish entry arrow colours for maximum visibility.
Tolerance Levels
Adjust symmetry and slope tolerance to refine how strict the channel rules are.
Tighter settings = fewer but cleaner zones.
Looser settings = more frequent setups, but with slightly lower structural quality.
Channel Glow Projection
Define how many bars forward the channel is drawn. This controls how far into the future your Wolfe zones are extended.
Stop Loss Line Length
Keep the SL visible without it extending infinitely across your chart.
Take Profit Line Colors
Each TP projection can be styled to your preference, allowing you to clearly separate TP1, TP2, and TP3.
This isn’t a one-size-fits-all tool. You can shape Wolfe detection logic to match the pairs, timeframes, and market conditions you trade most.
🚀 Why it’s different
Classic Wolfe waves are rare — this script adapts the model into something practical and tradeable in modern markets.
Liquidity-aligned — many setups align with structural sweeps of Wave 3 liquidity before driving into profit.
Entry built-in — most Wolfe scripts only draw the structure. Wolfe Wave Hunter gives you a precise entry point, SL, and projected TPs.
Backtest-friendly — you’ll quickly discover which assets respect Wolfe waves and which don’t, creating your own high-probability Wolfe watchlist.
⚠️ Limitations & Disclaimer
Not all markets respect Wolfe Waves. Some FX pairs, metals, and indices respect the structure beautifully; others do not. Backtest and create your own shortlist.
No guaranteed sweeps. Many entries occur after a liquidity sweep of Wave 3, but not all. The algo is designed to detect Wolfe completion, not enforce textbook liquidity rules.
Probabilistic, not predictive. Wolfe setups don’t win every time. Always use risk management.
High-RR focus. This is not a high-frequency tool. It’s designed for precision, asymmetric setups where risk is small and reward potential is large.
✅ The Bottom Line
Apex Edge – Wolfe Wave Hunter is a modern reimagination of the Wolfe Wave. It blends structural geometry, liquidity dynamics, and algo-driven execution into a single tool that:
Detects the pattern automatically
Provides SL, entry, and TP levels
Offers alerts for hands-off trading
Allows deep customisation for different markets
When it hits, it delivers outstanding risk-to-reward. Backtest, refine your tolerances, and build your watchlist of assets where Wolfe structures consistently pay.
This isn’t just Wolfe detection — it’s Wolfe trading, rebuilt for the modern trader.
Developer Notes - As always with the Apex Edge Brand, user feedback and recommendations will always be respected. Simply drop us a message with your comments and we will endeavour to address your needs in future version updates.
Swing Z – Crypto Trading Algorithm | Zillennial Technologies IncSwing Z by Zillennial Technologies Inc. is an advanced algorithmic framework built specifically for cryptocurrency markets. It integrates multiple layers of technical analysis into a single decision-support tool, generating buy and sell signals only when several independent confirmations align.
Core Concept
Swing Z fuses trend structure, momentum oscillators, volatility signals, and price action tools to capture high-probability trading opportunities in volatile crypto environments.
Trend Structure (EMA 9, 21, 50, 200)
Short-term EMAs (9 & 21) detect immediate momentum shifts.
Longer-term EMAs (50 & 200) define the broader trend and dynamic support/resistance.
Momentum & Confirmation Layer
RSI measures relative strength and market conditions.
MACD crossovers confirm momentum shifts and trend continuations.
Volatility & Market Pressure
TTM Squeeze highlights compression zones likely to precede breakouts.
Volume analysis confirms conviction behind directional moves.
VWAP (Volume Weighted Average Price) establishes intraday value zones and institutional benchmarks.
Price Action Filters
Fibonacci retracements are integrated to identify key reversal and continuation levels.
Signals are produced only when multiple conditions agree, reducing noise and improving reliability in fast-moving crypto markets.
Features
Tailored for cryptocurrency trading across major pairs (BTC, ETH, and altcoins).
Works effectively on swing and trend-based timeframes (1H–1D).
Combines trend, momentum, volatility, and price action into a single framework.
Generates clear Buy/Sell markers and integrates with TradingView alerts.
How to Use
Apply to a clean chart for the clearest visualization.
Use Swing Z as a swing trading tool, aligning entries with both trend structure and momentum confirmation.
Combine with your own stop-loss, take-profit, and position sizing rules.
Avoid application on non-standard chart types such as Renko, Heikin Ashi, or Point & Figure, which may distort results.
Disclaimer
Swing Z is designed as a decision-support tool, not financial advice.
All backtesting should use realistic risk, commission, and slippage assumptions.
Past results do not guarantee future performance.
Signals do not repaint but may adjust as new data develops in real-time.
Why Swing Z is original & useful:
Swing Z unifies EMA trend structure, RSI, MACD, TTM Squeeze, VWAP, Fibonacci retracements, and volume analysis into a single algorithmic framework. This multi-confirmation approach improves accuracy by requiring consensus across trend, momentum, volatility, and price action — a design made specifically for the challenges and volatility of cryptocurrency markets.
Mutanabby_AI | Algo Pro Strategy# Mutanabby_AI | Algo Pro Strategy: Advanced Candlestick Pattern Trading System
## Strategy Overview
The Mutanabby_AI Algo Pro Strategy represents a systematic approach to automated trading based on advanced candlestick pattern recognition and multi-layered technical filtering. This strategy transforms traditional engulfing pattern analysis into a comprehensive trading system with sophisticated risk management and flexible position sizing capabilities.
The strategy operates on a long-only basis, entering positions when bullish engulfing patterns meet specific technical criteria and exiting when bearish engulfing patterns indicate potential trend reversals. The system incorporates multiple confirmation layers to enhance signal reliability while providing comprehensive customization options for different trading approaches and risk management preferences.
## Core Algorithm Architecture
The strategy foundation relies on bullish and bearish engulfing candlestick pattern recognition enhanced through technical analysis filtering mechanisms. Entry signals require simultaneous satisfaction of four distinct criteria: confirmed bullish engulfing pattern formation, candle stability analysis indicating decisive price action, RSI momentum confirmation below specified thresholds, and price decline verification over adjustable lookback periods.
The candle stability index measures the ratio between candlestick body size and total range including wicks, ensuring only well-formed patterns with clear directional conviction generate trading signals. This filtering mechanism eliminates indecisive market conditions where pattern reliability diminishes significantly.
RSI integration provides momentum confirmation by requiring oversold conditions before entry signal generation, ensuring alignment between pattern formation and underlying momentum characteristics. The RSI threshold remains fully adjustable to accommodate different market conditions and volatility environments.
Price decline verification examines whether current prices have decreased over a specified period, confirming that bullish engulfing patterns occur after meaningful downward movement rather than during sideways consolidation phases. This requirement enhances the probability of successful reversal pattern completion.
## Advanced Position Management System
The strategy incorporates dual position sizing methodologies to accommodate different account sizes and risk management approaches. Percentage-based position sizing calculates trade quantities as equity percentages, enabling consistent risk exposure across varying account balances and market conditions. This approach proves particularly valuable for systematic trading approaches and portfolio management applications.
Fixed quantity sizing provides precise control over trade sizes independent of account equity fluctuations, offering predictable position management for specific trading strategies or when implementing precise risk allocation models. The system enables seamless switching between sizing methods through simple configuration adjustments.
Position quantity calculations integrate seamlessly with TradingView's strategy testing framework, ensuring accurate backtesting results and realistic performance evaluation across different market conditions and time periods. The implementation maintains consistency between historical testing and live trading applications.
## Comprehensive Risk Management Framework
The strategy features dual stop loss methodologies addressing different risk management philosophies and market analysis approaches. Entry price-based stop losses calculate stop levels as fixed percentages below entry prices, providing predictable risk exposure and consistent risk-reward ratio maintenance across all trades.
The percentage-based stop loss system enables precise risk control by limiting maximum loss per trade to predetermined levels regardless of market volatility or entry timing. This approach proves essential for systematic trading strategies requiring consistent risk parameters and capital preservation during adverse market conditions.
Lowest low-based stop losses identify recent price support levels by analyzing minimum prices over adjustable lookback periods, placing stops below these technical levels with additional buffer percentages. This methodology aligns stop placement with market structure rather than arbitrary percentage calculations, potentially improving stop loss effectiveness during normal market fluctuations.
The lookback period adjustment enables optimization for different timeframes and market characteristics, with shorter periods providing tighter stops for active trading and longer periods offering broader stops suitable for position trading approaches. Buffer percentage additions ensure stops remain below obvious support levels where other market participants might place similar orders.
## Visual Customization and Interface Design
The strategy provides comprehensive visual customization through eight predefined color schemes designed for different chart backgrounds and personal preferences. Color scheme options include Classic bright green and red combinations, Ocean themes featuring blue and orange contrasts, Sunset combinations using gold and crimson, and Neon schemes providing high visibility through bright color selections.
Professional color schemes such as Forest, Royal, and Fire themes offer sophisticated alternatives suitable for business presentations and professional trading environments. The Custom color scheme enables precise color selection through individual color picker controls, maintaining maximum flexibility for specific visual requirements.
Label styling options accommodate different chart analysis preferences through text bubble, triangle, and arrow display formats. Size adjustments range from tiny through huge settings, ensuring appropriate visual scaling across different screen resolutions and chart configurations. Text color customization maintains readability across various chart themes and background selections.
## Signal Quality Enhancement Features
The strategy incorporates signal filtering mechanisms designed to eliminate repetitive signal generation during choppy market conditions. The disable repeating signals option prevents consecutive identical signals until opposing conditions occur, reducing overtrading during consolidation phases and improving overall signal quality.
Signal confirmation requirements ensure all technical criteria align before trade execution, reducing false signal occurrence while maintaining reasonable trading frequency for active strategies. The multi-layered approach balances signal quality against opportunity frequency through adjustable parameter optimization.
Entry and exit visualization provides clear trade identification through customizable labels positioned at relevant price levels. Stop loss visualization displays active risk levels through colored line plots, ensuring complete transparency regarding current risk management parameters during live trading operations.
## Implementation Guidelines and Optimization
The strategy performs effectively across multiple timeframes with optimal results typically occurring on intermediate timeframes ranging from fifteen minutes through four hours. Higher timeframes provide more reliable pattern formation and reduced false signal occurrence, while lower timeframes increase trading frequency at the expense of some signal reliability.
Parameter optimization should focus on RSI threshold adjustments based on market volatility characteristics and candlestick pattern timeframe analysis. Higher RSI thresholds generate fewer but potentially higher quality signals, while lower thresholds increase signal frequency with corresponding reliability considerations.
Stop loss method selection depends on trading style preferences and market analysis philosophy. Entry price-based stops suit systematic approaches requiring consistent risk parameters, while lowest low-based stops align with technical analysis methodologies emphasizing market structure recognition.
## Performance Considerations and Risk Disclosure
The strategy operates exclusively on long positions, making it unsuitable for bear market conditions or extended downtrend periods. Users should consider market environment analysis and broader trend assessment before implementing the strategy during adverse market conditions.
Candlestick pattern reliability varies significantly across different market conditions, with higher reliability typically occurring during trending markets compared to ranging or volatile conditions. Strategy performance may deteriorate during periods of reduced pattern effectiveness or increased market noise.
Risk management through stop loss implementation remains essential for capital preservation during adverse market movements. The strategy does not guarantee profitable outcomes and requires proper position sizing and risk management to prevent significant capital loss during unfavorable trading periods.
## Technical Specifications
The strategy utilizes standard TradingView Pine Script functions ensuring compatibility across all supported instruments and timeframes. Default configuration employs 14-period RSI calculations, adjustable candle stability thresholds, and customizable price decline verification periods optimized for general market conditions.
Initial capital settings default to $10,000 with percentage-based equity allocation, though users can adjust these parameters based on account size and risk tolerance requirements. The strategy maintains detailed trade logs and performance metrics through TradingView's integrated backtesting framework.
Alert integration enables real-time notification of entry and exit signals, stop loss executions, and other significant trading events. The comprehensive alert system supports automated trading applications and manual trade management approaches through detailed signal information provision.
## Conclusion
The Mutanabby_AI Algo Pro Strategy provides a systematic framework for candlestick pattern trading with comprehensive risk management and position sizing flexibility. The strategy's strength lies in its multi-layered confirmation approach and sophisticated customization options, enabling adaptation to various trading styles and market conditions.
Successful implementation requires understanding of candlestick pattern analysis principles and appropriate parameter optimization for specific market characteristics. The strategy serves traders seeking automated execution of proven technical analysis techniques while maintaining comprehensive control over risk management and position sizing methodologies.

Trendline Breaks with Multi Fibonacci Supertrend StrategyTMFS Strategy: Advanced Trendline Breakouts with Multi-Fibonacci Supertrend
Elevate your algorithmic trading with institutional-grade signal confluence
Strategy Genesis & Evolution
This advanced trading system represents the culmination of a personal research journey, evolving from my custom " Multi Fibonacci Supertrend with Signals " indicator into a comprehensive trading strategy. Built upon the exceptional trendline detection methodology pioneered by LuxAlgo in their " Trendlines with Breaks " indicator, I've engineered a systematic framework that integrates multiple technical factors into a cohesive trading system.
Core Fibonacci Principles
At the heart of this strategy lies the Fibonacci sequence application to volatility measurement:
// Fibonacci-based factors for multiple Supertrend calculations
factor1 = input.float(0.618, 'Factor 1 (Weak/Fibonacci)', minval = 0.01, step = 0.01)
factor2 = input.float(1.618, 'Factor 2 (Medium/Golden Ratio)', minval = 0.01, step = 0.01)
factor3 = input.float(2.618, 'Factor 3 (Strong/Extended Fib)', minval = 0.01, step = 0.01)
These precise Fibonacci ratios create a dynamic volatility envelope that adapts to changing market conditions while maintaining mathematical harmony with natural price movements.
Dynamic Trendline Detection
The strategy incorporates LuxAlgo's pioneering approach to trendline detection:
// Pivotal swing detection (inspired by LuxAlgo)
pivot_high = ta.pivothigh(swing_length, swing_length)
pivot_low = ta.pivotlow(swing_length, swing_length)
// Dynamic slope calculation using ATR
slope = atr_value / swing_length * atr_multiplier
// Update trendlines based on pivot detection
if bool(pivot_high)
upper_slope := slope
upper_trendline := pivot_high
else
upper_trendline := nz(upper_trendline) - nz(upper_slope)
This adaptive trendline approach automatically identifies key structural market boundaries, adjusting in real-time to evolving chart patterns.
Breakout State Management
The strategy implements sophisticated state tracking for breakout detection:
// Track breakouts with state variables
var int upper_breakout_state = 0
var int lower_breakout_state = 0
// Update breakout state when price crosses trendlines
upper_breakout_state := bool(pivot_high) ? 0 : close > upper_trendline ? 1 : upper_breakout_state
lower_breakout_state := bool(pivot_low) ? 0 : close < lower_trendline ? 1 : lower_breakout_state
// Detect new breakouts (state transitions)
bool new_upper_breakout = upper_breakout_state > upper_breakout_state
bool new_lower_breakout = lower_breakout_state > lower_breakout_state
This state-based approach enables precise identification of the exact moment when price breaks through a significant trendline.
Multi-Factor Signal Confluence
Entry signals require confirmation from multiple technical factors:
// Define entry conditions with multi-factor confluence
long_entry_condition = enable_long_positions and
upper_breakout_state > upper_breakout_state and // New trendline breakout
di_plus > di_minus and // Bullish DMI confirmation
close > smoothed_trend // Price above Supertrend envelope
// Execute trades only with full confirmation
if long_entry_condition
strategy.entry('L', strategy.long, comment = "LONG")
This strict requirement for confluence significantly reduces false signals and improves the quality of trade entries.
Advanced Risk Management
The strategy includes sophisticated risk controls with multiple methodologies:
// Calculate stop loss based on selected method
get_long_stop_loss_price(base_price) =>
switch stop_loss_method
'PERC' => base_price * (1 - long_stop_loss_percent)
'ATR' => base_price - long_stop_loss_atr_multiplier * entry_atr
'RR' => base_price - (get_long_take_profit_price() - base_price) / long_risk_reward_ratio
=> na
// Implement trailing functionality
strategy.exit(
id = 'Long Take Profit / Stop Loss',
from_entry = 'L',
qty_percent = take_profit_quantity_percent,
limit = trailing_take_profit_enabled ? na : long_take_profit_price,
stop = long_stop_loss_price,
trail_price = trailing_take_profit_enabled ? long_take_profit_price : na,
trail_offset = trailing_take_profit_enabled ? long_trailing_tp_step_ticks : na,
comment = "TP/SL Triggered"
)
This flexible approach adapts to varying market conditions while providing comprehensive downside protection.
Performance Characteristics
Rigorous backtesting demonstrates exceptional capital appreciation potential with impressive risk-adjusted metrics:
Remarkable total return profile (1,517%+)
Strong Sortino ratio (3.691) indicating superior downside risk control
Profit factor of 1.924 across all trades (2.153 for long positions)
Win rate exceeding 35% with balanced distribution across varied market conditions
Institutional Considerations
The strategy architecture addresses execution complexities faced by institutional participants with temporal filtering and date-range capabilities:
// Time Filter settings with flexible timezone support
import jason5480/time_filters/5 as time_filter
src_timezone = input.string(defval = 'Exchange', title = 'Source Timezone')
dst_timezone = input.string(defval = 'Exchange', title = 'Destination Timezone')
// Date range filtering for precise execution windows
use_from_date = input.bool(defval = true, title = 'Enable Start Date')
from_date = input.time(defval = timestamp('01 Jan 2022 00:00'), title = 'Start Date')
// Validate trading permission based on temporal constraints
date_filter_approved = time_filter.is_in_date_range(
use_from_date, from_date, use_to_date, to_date, src_timezone, dst_timezone
)
These capabilities enable precise execution timing and market session optimization critical for larger market participants.
Acknowledgments
Special thanks to LuxAlgo for the pioneering work on trendline detection and breakout identification that inspired elements of this strategy. Their innovative approach to technical analysis provided a valuable foundation upon which I could build my Fibonacci-based methodology.
This strategy is shared under the same Attribution-NonCommercial-ShareAlike 4.0 International (CC BY-NC-SA 4.0) license as LuxAlgo's original work.
Past performance is not indicative of future results. Conduct thorough analysis before implementing any algorithmic strategy.

Ichimoku Score Indicator [tanayroy]The Ichimoku Cloud is a comprehensive indicator that provides a clear view of market states through five key components. By analyzing the interaction between these components and the asset's price, traders can gain insights into trend direction, momentum, and potential reversals.
Introducing the Ichimoku Score System
I have developed a scoring system that quantifies these interactions, offering an objective method to evaluate market conditions. The score is calculated based on the relative positioning of Ichimoku components, with adjustable weightings via user input.
Scoring Criteria
Each component contributes to the overall score as follows:
Price vs. Cloud (Kumo) & Other Components
Price vs. Kumo → 2 Points
Price vs. Kumo Shadow → 0.5 Points
Tenkan vs. Kijun
Tenkan vs. Kijun → 2 Points
Tenkan vs. Kumo → 0.5 Points
Kijun vs. Kumo → 0.5 Points
Tenkan Slope → 0.5 Points
Kijun Slope → 0.5 Points
Chikou Span Interactions
Price vs. Chikou → 2 Points
Chikou vs. Kumo → 0.5 Points
Chikou Consolidation → 0.5 Points
Senkou Span Analysis
Senkou A vs. Senkou B → 2 Points
Senkou Slope → 0.5 Points
Price vs. Key Levels
Price vs. Tenkan → 2 Points
Price vs. Kijun → 2 Points
Interpreting the Score
The aggregate score functions as an oscillator, fluctuating between a range of ±16.0.
A higher score indicates strong bullish momentum.
A lower score suggests bearish market conditions.
To enhance readability and smooth fluctuations, a 9-period SMA is applied to the score.
Application in Algorithmic Trading
This scoring system helps integrate Ichimoku Cloud principles into algorithmic trading strategies by providing a structured and quantifiable method for assessing market conditions.
Would love to hear your feedback! 🚀 Let me know how this system works for you.
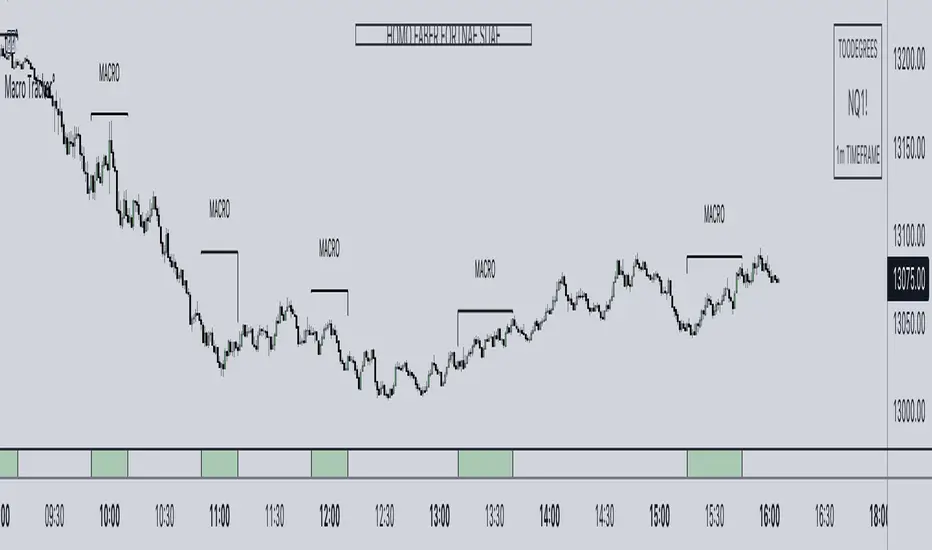
ICT Algorithmic Macro Tracker° (Open-Source) by toodegreesDescription:
The ICT Algorithmic Macro Tracker° Indicator is a powerful tool designed to enhance your trading experience by clearly and efficiently plotting the known ICT Macro Times on your chart.
Based on the teachings of the Inner Circle Trader , these Time windows correspond to periods when the Interbank Price Delivery Algorithm undergoes a series of checks ( Macros ) and is probable to move towards Liquidity.
The indicator allows traders to visualize and analyze these crucial moments in NY Time:
- 2:33-3:00
- 4:03-4:30
- 8:50-9:10
- 9:50-10:10
- 10:50-11:10
- 11:50-12:10
- 13:10-13:50
- 15:15-15:45
By providing a clean and clutter-free representation of ICT Macros, this indicator empowers traders to make more informed decisions, optimize and build their strategies based on Time.
Massive shoutout to @reastruth for his ICT Macros Indicator , and for allowing to create one of my own, go check him out!
Indicator Features:
– Track ongoing ICT Macros to aid your Live analysis.
- Gain valuable insights by hovering over the plotted ICT Macros to reveal tooltips with interval information.
– Plot the ICT Macros in one of two ways:
"On Chart": visualize ICT Macro timeframes directly on your chart, with automatic adjustments as Price moves.
Pro Tip: toggle Projections to see exactly where Macros begin and end without difficulty.
"New Pane": move the indicator two a New Pane to see both Live and Upcoming Macro events with ease in a dedicated section
Pro Tip: this section can be collapsed by double-clicking on the main chart, allowing for seamless trading preparation.
This indicator is available only on the TradingView platform.
⚠️ Open Source ⚠️
Coders and TV users are authorized to copy this code base, but a paid distribution is prohibited. A mention to the original author is expected, and appreciated.
⚠️ Terms and Conditions ⚠️
This financial tool is for educational purposes only and not financial advice. Users assume responsibility for decisions made based on the tool's information. Past performance doesn't guarantee future results. By using this tool, users agree to these terms.
MarkovAlgorithmLibrary "MarkovAlgorithm"
Markov algorithm is a string rewriting system that uses grammar-like rules to operate on strings of
symbols. Markov algorithms have been shown to be Turing-complete, which means that they are suitable as a
general model of computation and can represent any mathematical expression from its simple notation.
~ wikipedia
.
reference:
en.wikipedia.org
rosettacode.org
parse(rules, separator)
Parameters:
rules (string)
separator (string)
Returns: - `array _rules`: List of rules.
---
Usage:
- `parse("|0 -> 0||\n1 -> 0|\n0 -> ")`
apply(expression, rules)
Aplies rules to a expression.
Parameters:
expression (string) : `string`: Text expression to be formated by the rules.
rules (rule ) : `string`: Rules to apply to expression on a string format to be parsed.
Returns: - `string _result`: Formated expression.
---
Usage:
- `apply("101", parse("|0 -> 0||\n1 -> 0|\n0 -> "))`
apply(expression, rules)
Parameters:
expression (string)
rules (string)
Returns: - `string _result`: Formated expression.
---
Usage:
- `apply("101", parse("|0 -> 0||\n1 -> 0|\n0 -> "))`
rule
String pair that represents `pattern -> replace`, each rule may be ordinary or terminating.
Fields:
pattern (series string) : Pattern to replace.
replacement (series string) : Replacement patterns.
termination (series bool) : Termination rule.
Level 1 - Learn to code simply - PineScriptThe goal of this script is honestly to help everyone learn about trading with bots and algos.
At least, to get started.
Level 1:
10 lines of code.
learn to plot 2 moving averages on your chart.
learn to create a signal from a crossover.
learn the very basics of Pine Script algo.

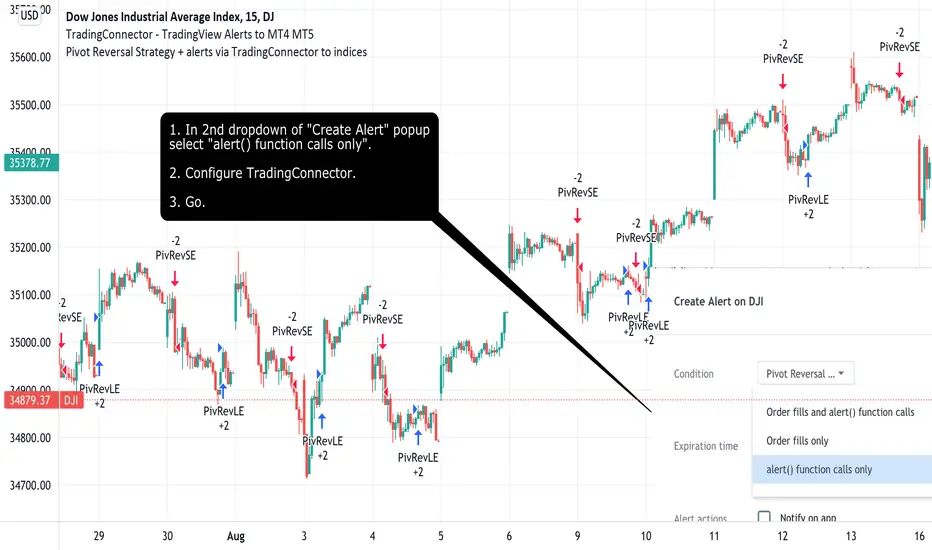
Pivot Reversal Strategy + alerts via TradingConnector to indicesSoftware part of algotrading is simpler than you think. TradingView is a great place to do this actually. To present it, I'm publishing each of the default strategies you can find in Pinescript editor's "built-in" list with slight modification - I'm only adding 2 lines of code, which will trigger alerts, ready to be forwarded to your broker via TradingConnector and instantly executed there. Alerts added in this script: 14 and 22.
How it works:
1. TradingView alert fires.
2. TradingConnector catches it and forwards to MetaTrader4/5 you got from your broker.
3. Trade gets executed inside MetaTrader within 1 second of fired alert.
When configuring alert, make sure to select "alert() function calls only" in CreateAlert popup. One alert per ticker is required.
Adding stop-loss, take-profit, trailing-stop, break-even or executing pending orders is also possible. These topics have been covered in other example posts.
This routing works for Forex, indices, stocks, crypto - anything your broker offers via their MetaTrader4 or 5.
Disclaimer: This concept is presented for educational purposes only. Profitable results of trading this strategy are not guaranteed even if the backtest suggests so. By no means this post can be considered a trading advice. You trade at your own risk.
If you are thinking to execute this particular strategy, make sure to find the instrument, settings and timeframe which you like most. You can do this by your own research only.
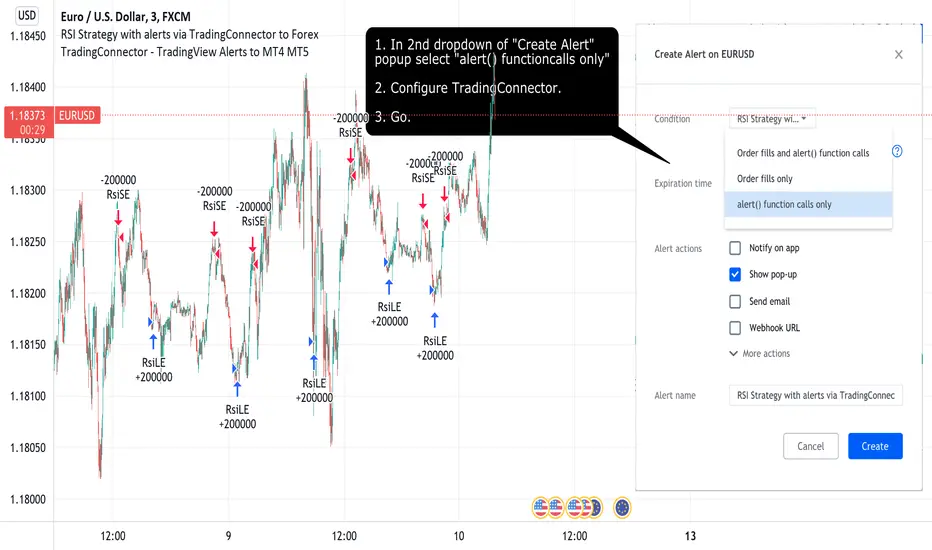
RSI Strategy with alerts via TradingConnector to ForexSoftware part of algotrading is simpler than you think. TradingView is a great place to do this actually. To present it, I'm publishing each of the default strategies you can find in Pinescript editor's "built-in" list with slight modification - I'm only adding 2 lines of code, which will trigger alerts, ready to be forwarded to your broker via TradingConnector and instantly executed there. Alerts added in this script: 12 and 17.
How it works:
1. TradingView alert fires.
2. TradingConnector catches it and forwards to MetaTrader4/5 you got from your broker.
3. Trade gets executed inside MetaTrader within 1 second of fired alert.
When configuring alert, make sure to select "alert() function calls only" in CreateAlert popup. One alert per ticker is required.
Adding stop-loss, take-profit, trailing-stop, break-even or executing pending orders is also possible. These topics have been covered in other example posts.
This routing works for Forex, indices, stocks, crypto - anything your broker offers via their MetaTrader4 or 5.
Disclaimer: This concept is presented for educational purposes only. Profitable results of trading this strategy are not guaranteed even if the backtest suggests so. By no means this post can be considered a trading advice. You trade at your own risk.
If you are thinking to execute this particular strategy, make sure to find the instrument, settings and timeframe which you like most. You can do this by your own research only.
function: Array DownsamplingA low cost function to down sample a array.
specially useful for pattern recognition algorithms.

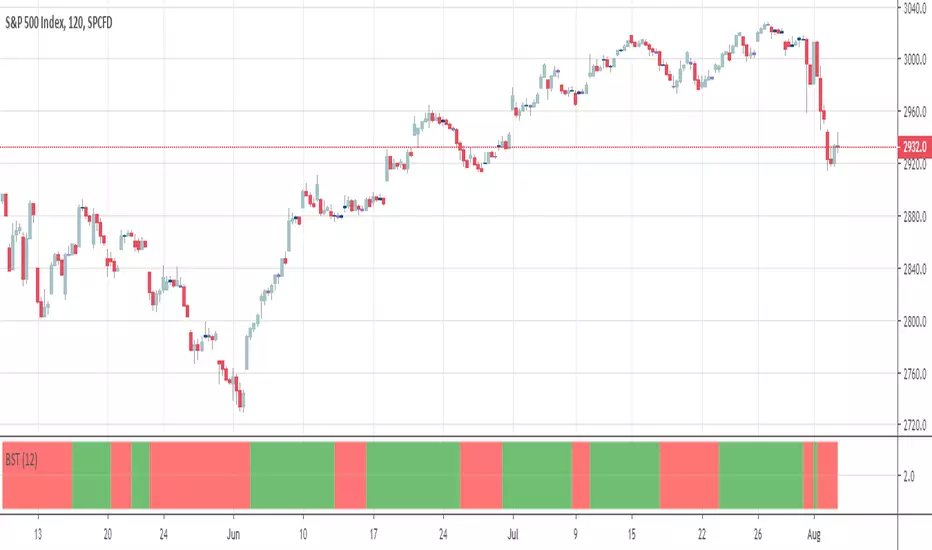
BSTtrend (and a quick note on trading psychology)Hi again :)
Script #2 for tonight, more to come :)
This one is a Pine transcription of a FXCM/LUA script called BSTrend
I used it years ago to trade index on very low timeframes with it. I'm always looking for oscillators that are more reactive than the traditional MACD. And even more reactive than the MACD Zero Lag
This is a proof of concept that Pinescript is my favorite trading programming language vs MT4/LUA/PRT. I just find it easier and the Pinescript community is helping a lot
With the BSTrend you can win but also lose. I see a lot of scripts out there but there is not a better or worst indicator. The key is HOW to use it.
In other words the key is your PSYCHOLOGY, without a rock-solid psychology, you'll end up committing a mistake even with G. himself whispering "BUY NOW", "SELL NOW" to your ears. (wait..... Do you mean this is happening only to me ????)
However, indicators help immensely in reducing the psychology pressure that we have to endure ... sometimes for days..... But better not to overcharge with dozens of indicators per chart and have a tool to detect whenever there is a confluence/convergence of your favorite indicators :) #algorithm #builder
I'll publish an educational post about next week
Those are the exact words that my mentor traders told me 6 years ago when I started trading
PS
____________________________________________________________
Be sure to hit the thumbs up as it shows me that I'm not doing this for nothing and will motivate to deliver more quality content in the future.
- I'm an officially approved PineEditor/LUA/MT4 approved mentor on codementor. You can request a coaching with me if you want and I'll teach you how to build kick-ass indicators and strategies
Jump on a 1 to 1 coaching with me
- You can also hire for a custom dev of your indicator/strategy/bot/chrome extension/python
[New series!] [Consistent Losing Strategies] 34 EMA Scalping//---------------------------INTRO------------------------------
Hi All!
Let me introduce myself as a semi-successful forex trader & lover of automation.
I've taken to algo trading and have been hunting down strategies (that usually use indicators) to automate, backtest, and hopefully implement in MT4.
Unfortunately, most strategies are complete bulls*** and the select cases that are shown to "prove" success are limited.
These strategy sources often do not provide useful analytics either.
I want to change that approach to trading! We can really benefit each other and the community by being methodical about backtesting
as well as evaluating our results with some kind of scoring heuristic.
As for what that standardized process looks like..well I'm still working on it.
I'm pretty much on Tv for multiple hours of the day, screening strategies via Pinescript and I'd like to start sharing my progress!
This is a new series I'd like to start on consistently losing strategies. I'll make all the code public, so if you think I've made a blunder
or approached a problem the wrong way, then drop me a DM or paste your fix into the comments.
//---------------------------STRAT------------------------------
34 EMA Scalping strategy (ref. forextradingstrategies4u )
How you're supposed to trade it:
BUY:
1. Market is in an down trend as shown by the 34 EMA
2. Price breaks above a downwards trend line
3. Price breaks above the 34 EMA
4. Look for a very bullish candlestick or chart pattern
SELL:
1. Look for the 34 EMA to show we are in an uptrend
2. Price breaks below an upwards sloping trend line
3. Price breaks below 34 EMA
4. Look for a bearish candlestick or a chart pattern
//---------------------------CONC------------------------------
Q: Why does it fail?
A: I believe this strategy relies too much on subjective input (aka, trendlines).
Q: Why does it fail as an algo?
A: The 34 EMA is no more predictive than any other EMA, although it does a good job at filtering out noise.
Q: Should I try it out?
A: No, it's trash. This is the proof that it is trash.

Adaptive AI SuperTrend [AlgoPoint]🚀 Adaptive AI SuperTrend
Adaptive AI SuperTrend is a high-performance trading terminal that redefines trend-following by integrating Machine Learning (ML) principles with advanced market regime detection. Unlike static indicators, this system dynamically recalibrates its internal parameters to match the ever-changing volatility of the financial markets.
Equipped with a custom "Wizard Engine," it filters out market noise during consolidation and identifies high-probability trend continuation points, making it an essential tool for scalpers, day traders, and swing traders alike.
🧠 What Makes it "AI"?
While traditional indicators use fixed rules, Adaptive AI SuperTrend utilizes Algorithmic Intelligence to make real-time decisions:
KNN-Inspired Adaptation: The engine analyzes the last 150 bars of volatility and trend strength to automatically adjust its sensitivity.
Market Regime Intelligence: It distinguishes between "Trending" and "Ranging" states using a sophisticated Squeeze Momentum module, preventing "whipsaws" during low-volume periods.
Self-Backtesting Logic: The indicator continuously calculates its own historical Win-Rate. If the probability of success falls below a certain threshold, it suppresses lower-quality signals.
🛠 Key Features
Dynamic Consolidation Boxes: Automatically identifies and wraps "choppy" price action in professional gray boxes. It waits for 3+ bars of consolidation before marking the zone, helping you spot breakout opportunities early.
Multi-Strategy Aggression:
- Conservative: Filtered signals for long-term trend following.
- Balanced: Optimized for daily volatility.
- Aggressive: High-frequency signals for capturing micro-trends.
Dual-Exit Risk Management:
- ATR TP-SL Mode: Sets mathematical targets based on market volatility with persistent on-screen lines.
- Smart Trailing Mode: Rides the trend to its exhaustion point. Includes intelligent labeling (🎯 TP or 🛑 SL) based on the trade's net profitability.
- RSI Pullback Confirmation: Beyond simple trend flips, it detects "buy the dip" or "sell the rip" opportunities within an existing trend using RSI 50-level crossovers.
📊 Real-Time Analytics Dashboard
The integrated AlgoPoint Dashboard provides a surgical view of the market:
- Market State: Instant "Trending" vs. "Ranging" (Consolidation) detection.
- Trend Strength: ADX-based momentum tracking.
- Strategy Status: Real-time feedback on your active aggression and exit modes.
🎨 Clean Charting & Customization
Built for professional clarity, you have total control over the UI:
Toggle Consolidation Boxes on/off.
Toggle ATR Target Lines and Exit Labels.
Customize background filters and dashboard visibility.

ICT Macro Slot Algo Event📊 Overview
A powerful multi-timeframe trading indicator that combines Institutional Macro Session Tracking identify optimal trading windows throughout the day. This tool helps traders align with institutional flow patterns and algorithmic activity across major sessions.
🎯 Key Features
1. Macro Algo Event Sessions
Tracks 6 key institutional time windows during NY Session:
NY Sweep (08:50-09:10) - Opening balance flows
Silver Bullet #1 (09:50-10:10) - First major macro move
Silver Bullet #2 (10:50-11:10) - Second chance/retest opportunity
Lunch Macro (11:50-12:10) - Mid-day repositioning
Post-Lunch Rebalance (13:10-13:40) - Post-lunch adjustments
NY Closing Macros (15:15-15:45) - End-of-day flows

ICT Macro Slot Algo Event📊 Overview
A powerful multi-timeframe trading indicator that combines Institutional Macro Session Tracking to identify optimal trading windows throughout the day. This tool helps traders align with institutional flow patterns and algorithmic activity across major sessions.
🎯 Key Features
1. Macro Algo Event Sessions
Tracks 6 key institutional time windows during NY Session:
NY Sweep (08:50-09:10) - Opening balance flows
Silver Bullet #1 (09:50-10:10) - First major macro move
Silver Bullet #2 (10:50-11:10) - Second chance/retest opportunity
Lunch Macro (11:50-12:10) - Mid-day repositioning
Post-Lunch Rebalance (13:10-13:40) - Post-lunch adjustments
NY Closing Macros (15:15-15:45) - End-of-day flows

Smart Cloud by Ilker (Custom Matriks)A Proprietary Hybrid Trend System for All Major Financial Assets
This indicator, originally developed for the Matriks platform, is a highly effective hybrid trend identification system designed for day-to-day analysis across all major asset classes, including Stocks, Forex, Indices, and Cryptocurrencies. It combines the forward-looking principle of the Ichimoku Kinko Hyo Cloud with heavily smoothed Moving Averages (MAs) to create a clear, visually guided trading signal. (Daily Timeframe recommended for optimal results).
📊 Algorithmic Structure and Parameters
The "Smart Cloud" utilizes six primary user-adjustable parameters that govern its sensitivity and shape, moving away from standard Ichimoku settings to provide a robust, customized trend view:
P1, P2, P3 (60, 56, 248): These long-term settings define the core structure and width of the cloud, acting as the primary dynamic support and resistance zone. The significantly longer P3 (Lagging Period) ensures the cloud reflects strong, deep market cycles.
P4 (Displacement 26): Maintains the traditional Ichimoku principle of projecting the cloud 26 periods forward to provide a predictive view of future trend support/resistance.
P5 (MA50 - Blue) & P6 (MA10 - Purple): These are the two primary Moving Averages plotted inside the cloud. They serve as fast-response momentum lines:
P5 (MA50): Represents the middle-term trend average.
P6 (MA10): Represents the short-term market momentum.
📈 Core Trend and Signal Interpretation
The indicator provides powerful trend identification based on three key components:
The Cloud (Kumo):
Green Cloud (Bullish): Indicates the dominant trend is up, suggesting dynamic support for price action.
Red Cloud (Bearish): Indicates the dominant trend is down, suggesting dynamic resistance.
The thickness and slope of the cloud are key indicators of trend strength.
MA Crossover Signal (Blue/Purple):
Buy Signal: When the faster Purple MA (P6=10) crosses above the slower Blue MA (P5=50).
Sell Signal: When the faster Purple MA (P6=10) crosses below the slower Blue MA (P5=50).
Price Action & Confirmation:
The most powerful signals occur when a MA Crossover is confirmed by price breaking out of the cloud in the same direction.
Price above the cloud and MA crossover to the upside suggests a strong buy entry.
Disclaimer: This tool is intended for analysis and decision-making support. It is not financial advice. Always use stop-loss orders and manage your risk accordingly.

Follow-up Buy / Sell Volume Pressure at Supply / Demand Zones█ Overview:
BE-Volume Footprint & Pressure Candles, is an indicator which is preliminarily designed to analyze the supply and demand patterns based on Rally Base Rally (RBR), Drop Base Drop (DBD), Drop Base Rally (DBR) & Rally Base Drop (RBD) concepts in conjunction to volume pressure. Understanding these concepts are crucial. Let's break down why the "Base" is you Best friend in this context.
Commonness in RBR, DBD, DBR, RBD patterns ?
There is an impulse price movement at first, be it rally (price moving up) or the Drop (price moving down), followed by a period of consolidation which is referred as "BASE" and later with another impulse move of price (Rally or Drop).
Why is the Base Important
1. Market Balance: Base represents a balance between buyers and sellers. This is where decisions are made.
2. Confirmation: It confirms the strength of previous impulse move which has happened.
Base & the Liquidity Play:
Supply & Demand Zone predict the presence of all large orders within the limits of the Base Zone. Price is expected to return to the zone to fill the unfilled orders placed by large players.
For the price to move in the intended direction Liquidity plays the major role. hence indicator aims to help traders in identifying those zones where liquidity exists and the volume pressure helps in confirming that liquidity is making its play.
Bottom pane in the below snapshots is a visual representation of Buyers volume pressure (Green Line & the Green filled area) making the price move upwards vs Sellers volume pressure (Red Line & the Red filled area) making the price move downwards.
Top pane in the below snapshots is a visual representation on the pattern identification (Blue marked zone & the Blue line referred as Liquidity level)
Bullish Pressure On Buy Liquidity:
Bearish Pressure On Sell Liquidity:
█ How It Works:
1. Indicator computes technical & mathematical operations such as ATR, delta of Highs & Lows of the candle and Candle ranges to identify the patterns and marks the liquidity lines accordingly.
2. Indicator then waits for price to return to the liquidity levels and checks if Directional volume pressure to flow-in while the prices hover near the Liquidity zones.
3. Once the Volume pressure is evident, loop in to the ride.
█ When It wont Work:
When there no sufficient Liquidity or sustained Opposite volume pressure, trades are expected to fail.
█ Limitations:
Works only on the scripts which has volume info. Relays on LTF candles to determine intra-bar volumes. Hence, Use on TF greater than 1 min and lesser than 15 min.
█ Indicator Features:
1. StrictEntries: employs' tighter rules (rather most significant setups) on the directional volume pressure applied for the price to move. If unchecked, liberal rules applied on the directional volume pressure leading to more setups being identified.
2. Setup Confirmation period: Indicates Waiting period to analyze the directional volume pressure. Early (lesser wait period) is Risky and Late (longer wait period) is too late for the
ride. Find the quant based on the accuracy of the setup provided in the bottom right table.
3. Algo Enabled with Place Holders:
Indicator is equipped with algo alerts, supported with necessary placeholders to trade any instrument like stock, options etc.
Accepted PlaceHolders (Case Sensitive!!)
1. {{ticker}}-->InstrumentName
2. {{datetime}}-->Date & Time Of Order Placement
3. {{close}}-->LTP Price of Script
4. {{TD}}-->Current Level:
Note: Negative Numbers for Short Setup
5. {{EN}} {{SL}} {{TGT}} {{T1}} {{T2}} --> Trade Levels
6. {{Qty}} {{Qty*x}} --> Qty -> Trade Qty mapped in Settings. Replace x with actual number of your choice for the multiplier
7. {{BS}}-->Based on the Direction of Trade Output shall be with B or S (B == Long Trade & S == Short Trade)
8. {{BUYSELL}}-->Based on the Direction of Trade Output shall be with BUY or SELL (BUY == Long Trade & SELL == Short Trade)
9. {{IBUYSELL}}-->Based on the Direction of Trade Output shall be with BUY or SELL (BUY == SHORT Trade & SELL == LONG Trade)
Dynamic Alerts:
10. { {100R0} }-->Dynamic Place Holder 100 Refers to Strike Difference and Zero refers to ATM
11. { {100R-1} }-->Dynamic Place Holder 100 Refers to Strike Difference and -1 refers to
ATM - 100 strike
12. { {50R2} }-->Dynamic Place Holder 50 Refers to Strike Difference and 2 refers to
ATM + (2 * 50 = 100) strike
13. { {"ddMMyy", 0} }-->Dynamically Picks today date in the specified format.
14. { {"ddMMyy", n} }-->replace n with actual number of your choice to Pick date post today date in the specified format.
15. { {"ddMMyy", "MON"} }-->dynamically pick Monday date (coming Monday, if today is not Monday)
Note. for the 2nd Param-->you can choose to specify either Number OR any letter from =>
16. {{CEPE}} {{ICEPE}} {{CP}} {{ICP}} -> Dynamic Option Side CE or C refers to Calls and PE or P refers to Puts. If "I" is used in PlaceHolder text, On long entries PUTs shall be used
Indicator is equipped with customizable Trade & Risk management settings like multiple Take profit levels, Trailing SL.

Apex Edge – Liquidity RaiderApex Edge – Liquidity Raider
The Predator That Hunts Where Retail Never Looks
The Liquidity Raider is not your average liquidity line plotter.
This is an institutional-grade hunting system that tracks the pools of liquidity Smart Money algos stalk — and tells you exactly when price is circling in for the strike.
Where most retail tools simply mark lines, this one acts like a predator:
Scans the chart dynamically to detect clustered highs & lows (pivot-based liquidity zones).
Filters noise with sensitivity & price rounding so you only get real liquidity levels — not every random swing.
Plots live BSL (Buy-Side Liquidity) & SSL (Sell-Side Liquidity) lines in clean dotted format.
Auto-deletes levels when swept, so your chart stays clean and focused.
Triggers directional arrows when price comes within your specified % distance to the target liquidity pool — before the market moves.
EMA confluence layer lets you align with institutional flow (customizable Fast & Slow EMAs).
Core Power
Cluster Logic – Finds high-probability liquidity zones using repeated pivot levels.
Sweep Awareness – Lines vanish the moment liquidity is taken, keeping focus on the next pool.
Proximity Strike Detection – Arrow signals only when price is within striking range.
Directional Clarity – Red arrows = targeting BSL, Green arrows = targeting SSL.
Scalable Across Timeframes – Adapts to your chart’s timeframe with dynamic lookback scaling.
Institutional Flow Filter – Optional EMA confirmation keeps you aligned with the real trend.
How to Use
Identify liquidity pools – Dotted green = buy-side, dotted red = sell-side.
Watch proximity arrows – These mean price is in range and hunting that pool.
Align with EMA bias – Enter only in the direction of institutional momentum.
Target the sweep – Your take profit is where the liquidity is resting.
Why Liquidity Raider Wins
This is not a lagging signal system.
It’s a real-time, clean, predictive tool designed to mimic the targeting logic of high-frequency algos.
By removing swept levels and focusing only on the next available pools, Liquidity Raider keeps you one step ahead of the crowd — and perfectly positioned for the kill shot.
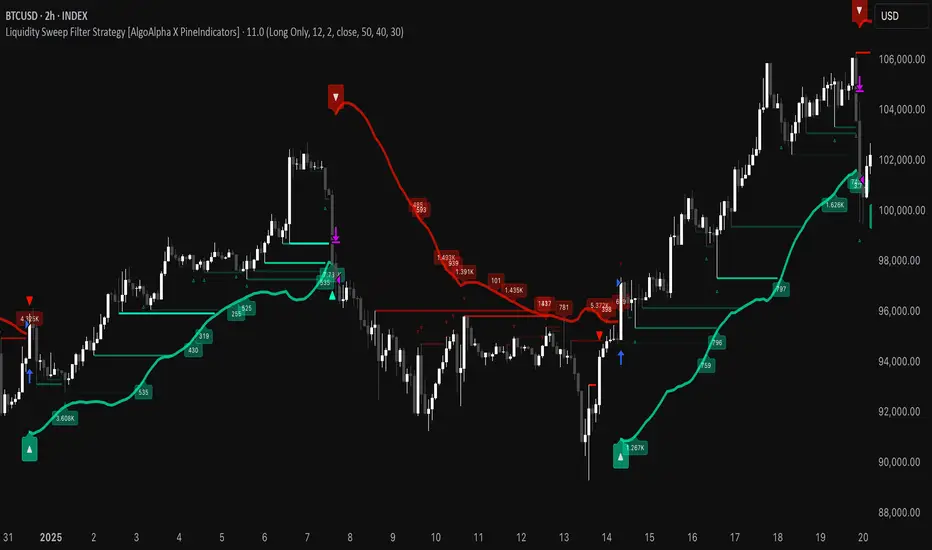
Liquidity Sweep Filter Strategy [AlgoAlpha X PineIndicators]This strategy is based on the Liquidity Sweep Filter developed by AlgoAlpha. Full credit for the concept and original indicator goes to AlgoAlpha.
The Liquidity Sweep Filter Strategy is a non-repainting trading system designed to identify liquidity sweeps, trend shifts, and high-impact price levels. It incorporates volume-based liquidation analysis, trend confirmation, and dynamic support/resistance detection to optimize trade entries and exits.
This strategy helps traders:
Detect liquidity sweeps where major market participants trigger stop losses and liquidations.
Identify trend shifts using a volatility-based moving average system.
Analyze volume distribution with a built-in volume profile visualization.
Filter noise by differentiating between major and minor liquidity sweeps.
How the Liquidity Sweep Filter Strategy Works
1. Trend Detection Using Volatility-Based Filtering
The strategy applies a volatility-adjusted moving average system to determine trend direction:
A central trend line is calculated using an EMA smoothed over a user-defined length.
Upper and lower deviation bands are created based on the average price deviation over multiple periods.
If price closes above the upper band, the strategy signals an uptrend.
If price closes below the lower band, the strategy signals a downtrend.
This approach ensures that trend shifts are confirmed only when price significantly moves beyond normal market fluctuations.
2. Liquidity Sweep Detection
Liquidity sweeps occur when price temporarily breaks key levels, triggering stop-loss liquidations or margin call events. The strategy tracks swing highs and lows, marking potential liquidity grabs:
Bearish Liquidity Sweeps – Price breaks a recent high, then reverses downward.
Bullish Liquidity Sweeps – Price breaks a recent low, then reverses upward.
Volume Integration – The strategy analyzes trading volume at each sweep to differentiate between major and minor sweeps.
Key levels where liquidity sweeps occur are plotted as color-coded horizontal lines:
Red lines indicate bearish liquidity sweeps.
Green lines indicate bullish liquidity sweeps.
Labels are displayed at each sweep, showing the volume of liquidated positions at that level.
3. Volume Profile Analysis
The strategy includes an optional volume profile visualization, displaying how trading volume is distributed across different price levels.
Features of the volume profile:
Point of Control (POC) – The price level with the highest traded volume is marked as a key area of interest.
Bounding Box – The profile is enclosed within a transparent box, helping traders visualize the price range of high trading activity.
Customizable Resolution & Scale – Traders can adjust the granularity of the profile to match their preferred time frame.
The volume profile helps identify zones of strong support and resistance, making it easier to anticipate price reactions at key levels.
Trade Entry & Exit Conditions
The strategy allows traders to configure trade direction:
Long Only – Only takes long trades.
Short Only – Only takes short trades.
Long & Short – Trades in both directions.
Entry Conditions
Long Entry:
A bullish trend shift is confirmed.
A bullish liquidity sweep occurs (price sweeps below a key level and reverses).
The trade direction setting allows long trades.
Short Entry:
A bearish trend shift is confirmed.
A bearish liquidity sweep occurs (price sweeps above a key level and reverses).
The trade direction setting allows short trades.
Exit Conditions
Closing a Long Position:
A bearish trend shift occurs.
The position is liquidated at a predefined liquidity sweep level.
Closing a Short Position:
A bullish trend shift occurs.
The position is liquidated at a predefined liquidity sweep level.
Customization Options
The strategy offers multiple adjustable settings:
Trade Mode: Choose between Long Only, Short Only, or Long & Short.
Trend Calculation Length & Multiplier: Adjust how trend signals are calculated.
Liquidity Sweep Sensitivity: Customize how aggressively the strategy identifies sweeps.
Volume Profile Display: Enable or disable the volume profile visualization.
Bounding Box & Scaling: Control the size and position of the volume profile.
Color Customization: Adjust colors for bullish and bearish signals.
Considerations & Limitations
Liquidity sweeps do not always result in reversals. Some price sweeps may continue in the same direction.
Works best in volatile markets. In low-volatility environments, liquidity sweeps may be less reliable.
Trend confirmation adds a slight delay. The strategy ensures valid signals, but this may result in slightly later entries.
Large volume imbalances may distort the volume profile. Adjusting the scale settings can help improve visualization.
Conclusion
The Liquidity Sweep Filter Strategy is a volume-integrated trading system that combines liquidity sweeps, trend analysis, and volume profile data to optimize trade execution.
By identifying key price levels where liquidations occur, this strategy provides valuable insight into market behavior, helping traders make better-informed trading decisions.
Key use cases for this strategy:
Liquidity-Based Trading – Capturing moves triggered by stop hunts and liquidations.
Volume Analysis – Using volume profile data to confirm high-activity price zones.
Trend Following – Entering trades based on confirmed trend shifts.
Support & Resistance Trading – Using liquidity sweep levels as dynamic price zones.
This strategy is fully customizable, allowing traders to adapt it to different market conditions, timeframes, and risk preferences.
Full credit for the original concept and indicator goes to AlgoAlpha.
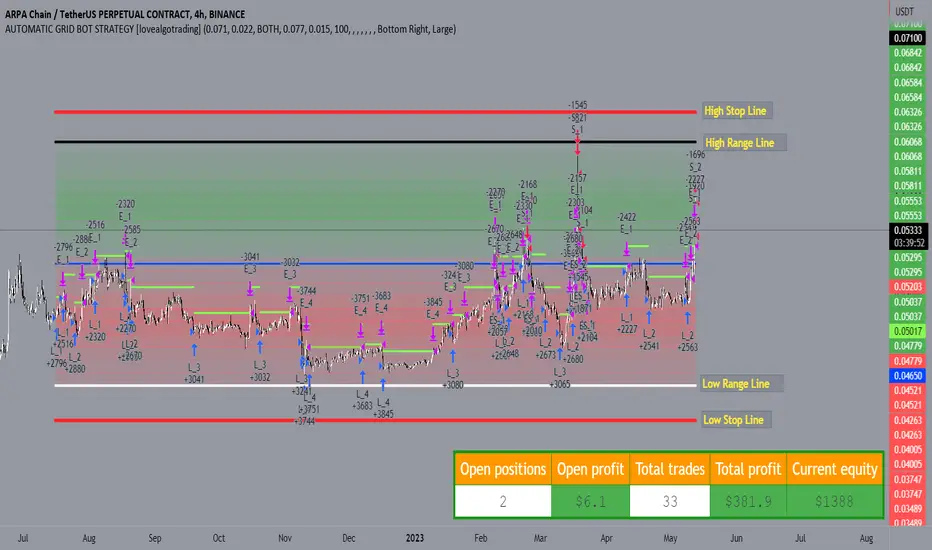
AUTOMATIC GRID BOT STRATEGY [ilovealgotrading]
OVERVIEW:
This Grid trading strategy can help you maximize your profit in a ranging sideways market with no clear direction.
INDICATOR:
We can get some money by taking advantage of the movement of the price between the range we have determined.
Short positions are opened while the price is rising, long positions are opened while the price is falling.
Therefore, there is no need to predict the trend direction.
What is different in this indicator:
I want to say thank you to © thequantscience. His GRID SPOT TRADING ALGORITHM - GRID BOT TRADING strategy helped me when I was writing my indicator.
I want to explain what I have improved:
1- Grid strategy is a type of strategy that can be traded in very short time frames and users can trade this strategy algorithmically by connecting this strategy to their own accounts with the help of API systems. For this reason, I have developed a software that can give us signals by dynamically changing the long and short messages when users are trading.
2- We can change the start and end dates of our grid bot as we want. It is necessary to use this setting when setting up automatic bots, so that previously opened transactions are not taken into account.
3 - Lot or quantity size should not be excessively small when users are taking automatic trades because exchanges have limitations, to avoid this problem, I have prevented this error by automatically rounding up to the nearest quantity size inside the software.
4 - Users can avoid excessive losses by using stop loss on this grid bot if they wish.
5 - When our price is over the range high or below the range low, our open positions are closed, if the stop button is active. We can also change which close price time frame we take as a basis from the settings.
6 -Users can set how many dollars they can enter per transaction while performing their transactions automatically.
IMPLEMENTATION DETAILS – SETTINGS:
This script allows the user to choose the highs and lows leves of our range. Our bot trades in the specified range.
1. This strategy allows us to set start and end backtest dates.
2. We can change range high and range low leves of our bot
3. IF people want to trade algorithmically with the help of this bot, there are 6 different input systems that will receive the Json codes as an alarm
4. IF the price closes above the upper line or below the lower line, all transactions will be closed. We can determine in which time frame our transactions will be stopped if the price closes outside these levels.We can adjust how our bot works by activating or turning off the Stop Loss button.
5. In this strategy, you can determine your dollar cost for per position.
6. The user can also divide the interval we have determined into 10 parts or 20 equal parts.
7. The grid is divided and colored at the interval we set. At the same time, if we don't want we can turn off colored channels.
Notes:
If you're going to connect this bot to an automatic Long and Short direction,
Don’t forget! you need to Webhook URL,
Don’t miss paste this code to your message window {{strategy.order.alert_message}}
ALSO:
Set your range below the support zones and above the resistance zones.
Don't be afraid to take a wide range, it doesn't matter if you make a little money, the important thing is that you don't lose money.
If you have any ideas what to add to my work to add more sources or make calculations cooler, suggest in DM .