OPEN-SOURCE SCRIPT
Hybrid Adaptive Double Exponential Smoothing
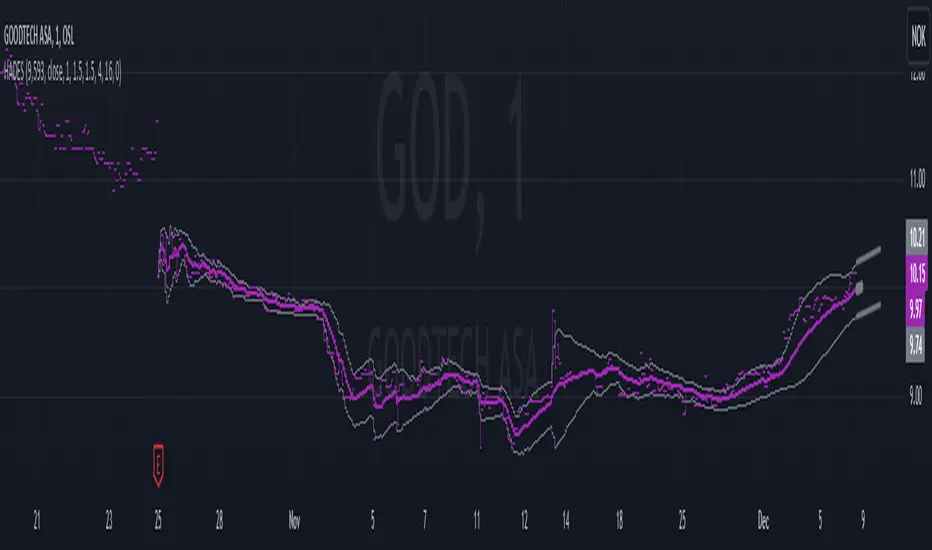
🙏🏻 This is HADES (Hybrid Adaptive Double Exponential Smoothing): fully data-driven & adaptive exponential smoothing method, that gains all the necessary info directly from data in the most natural way and needs no subjective parameters & no optimizations. It gets applied to data itself -> to fit residuals & one-point forecast errors, all at O(1) algo complexity. I designed it for streaming high-frequency univariate time series data, such as medical sensor readings, orderbook data, tick charts, requests generated by a backend, etc.
The HADES method is:
fit & forecast = a + b * (1 / alpha + T - 1)
T = 0 provides in-sample fit for the current datum, and T + n[1, inf] provides forecast for n datapoints.
y = input time series
a[t-1] = y, if no previous data exists
b[t-1] = 0, if no previous data exists
otherwise:
a = alpha * y + (1 - alpha) * a[t-1]
b = alpha * (a - a[t-1]) + (1 - alpha) * b[t-1]
alpha = 1 / sqrt(len * 4)
len = min(ceil(exp(1 / sig)), available data)
sig = sqrt(Absolute net change in y / Sum of absolute changes in y)
For the start datapoint when both numerator and denominator are zeros, we define 0 / 0 = 1
...
The same set of operations gets applied to the data first, then to resulting fit absolute residuals to build prediction interval, and finally to absolute forecasting errors (from one-point ahead forecast) to build forecasting interval:
prediction interval = data fit +- resoduals fit * k
forecasting interval = data opf +- errors fit * k
where k = multiplier regulating intervals width, and opf = one-point forecasts calculated at each time t
...
How-to:
0) Apply to your data where it makes sense, eg. tick data;
1) Use power transform to compensate for multiplicative behavior in case it's there;
2) If you have complete data or only the data you need, like the full history of adjusted close prices: go to the next step; otherwise, guided by your goal & analysis, adjust the 'start index' setting so the calculations will start from this point;
3) Use prediction interval to detect significant deviations from the process core & make decisions according to your strategy;
4) Use one-point forecast for nowcasting;
5) Use forecasting intervals to ~ understand where the next datapoints will emerge, given the data-generating process will stay the same & lack structural breaks.
I advise k = 1 or 1.5 or 4 depending on your goal, but 1 is the most natural one.
...
Why exponential smoothing at all? Why the double one? Why adaptive? Why not Holt's method?
1) It's O(1) algo complexity & recursive nature allows it to be applied in an online fashion to high-frequency streaming data; otherwise, it makes more sense to use other methods;
2) Double exponential smoothing ensures we are taking trends into account; also, in order to model more complex time series patterns such as seasonality, we need detrended data, and this method can be used to do it;
3) The goal of adaptivity is to eliminate the window size question, in cases where it doesn't make sense to use cumulative moving typical value;
4) Holt's method creates a certain interaction between level and trend components, so its results lack symmetry and similarity with other non-recursive methods such as quantile regression or linear regression. Instead, I decided to base my work on the original double exponential smoothing method published by Rob Brown in 1956, here's the original source, it's really hard to find it online. This cool dude is considered the one who've dropped exponential smoothing to open access for the first time🤘🏻
R&D log & explanations
If you wanna read this, you gotta know, you're taking a great responsability for this long journey, and it gonna be one hell of a trip hehe
Machine learning, apprentissage automatique, машинное обучение, digital signal processing, statistical learning, data mining, deep learning, etc., etc., etc.: all these are just artificial categories created by the local population of this wonderful world, but what really separates entities globally in the Universe is solution complexity / algorithmic complexity.
In order to get the game a lil better, it's gonna be useful to read the HTES script description first. Secondly, let me guide you through the whole R&D process.
To discover (not to invent) the fundamental universal principle of what exponential smoothing really IS, it required the review of the whole concept, understanding that many things don't add up and don't make much sense in currently available mainstream info, and building it all from the beginning while avoiding these very basic logical & implementation flaws.
Given a complete time t, and yet, always growing time series population that can't be logically separated into subpopulations, the very first question is, 'What amount of data do we need to utilize at time t?'. Two answers: 1 and all. You can't really gain much info from 1 datum, so go for the second answer: we need the whole dataset.
So, given the sequential & incremental nature of time series, the very first and basic thing we can do on the whole dataset is to calculate a cumulative <typical value>, such as cumulative moving mean or cumulative moving median.
Now we need to extend this logic to exponential smoothing, which doesn't use dataset length info directly, but all cool it can be done via a formula that quantifies the relationship between alpha (smoothing parameter) and length. The popular formulas used in mainstream are:
alpha = 1 / length
alpha = 2 / (length + 1)
The funny part starts when you realize that Cumulative Exponential Moving Averages with these 2 alpha formulas Exactly match Cumulative Moving Average and Cumulative (Linearly) Weighted Moving Average, and the same logic goes on:
alpha = 3 / (length + 1.5), matches Cumulative Weighted Moving Average with quadratic weights, and
alpha = 4 / (length + 2), matches Cumulative Weighted Moving Average with cubic weghts, and so on...
It all just cries in your shoulder that we need to discover another, native length->alpha formula that leverages the recursive nature of exponential smoothing, because otherwise, it doesn't make sense to use it at all, since the usual CMA and CMWA can be computed incrementally at O(1) algo complexity just as exponential smoothing.
From now on I will not mention 'cumulative' or 'linearly weighted / weighted' anymore, it's gonna be implied all the time unless stated otherwise.
What we can do is to approach the thing logically and model the response with a little help from synthetic data, a sine wave would suffice. Then we can think of relationships: Based on algo complexity from lower to higher, we have this sequence: exponential smoothing @ O(1) -> parametric statistics (mean) @ O(n) -> non-parametric statistics (50th percentile / median) @ O(n log n). Based on Initial response from slow to fast: mean -> median Based on convergence with the real expected value from slow to fast: mean (infinitely approaches it) -> median (gets it quite fast).
Based on these inputs, we need to discover such a length->alpha formula so the resulting fit will have the slowest initial response out of all 3, and have the slowest convergence with expected value out of all 3. In order to do it, we need to have some non-linear transformer in our formula (like a square root) and a couple of factors to modify the response the way we need. I ended up with this formula to meet all our requirements:
alpha = sqrt(1 / length * 2) / 2
which simplifies to:
alpha = 1 / sqrt(len * 8)

^^ as you can see on the screenshot; where the red line is median, the blue line is the mean, and the purple line is exponential smoothing with the formulas you've just seen, we've met all the requirements.
Now we just have to do the same procedure to discover the length->alpha formula but for double exponential smoothing, which models trends as well, not just level as in single exponential smoothing. For this comparison, we need to use linear regression and quantile regression instead of the mean and median.
Quantile regression requires a non-closed form solution to be solved that you can't really implement in Pine Script, but that's ok, so I made the tests using Python & sklearn:
paste.pics/SHHXB
^^ on this screenshot, you can see the same relationship as on the previous screenshot, but now between the responses of quantile regression & linear regression.
I followed the same logic as before for designing alpha for double exponential smoothing (also considered the initial overshoots, but that's a little detail), and ended up with this formula:
alpha = sqrt(1 / length) / 2
which simplifies to:
alpha = 1 / sqrt(len * 4)
Btw, given the pattern you see in the resulting formulas for single and double exponential smoothing, if you ever want to do triple (not Holt & Winters) exponential smoothing, you'll need len * 2, and just len * 1 for quadruple exponential smoothing. I hope that based on this sequence, you see the hint that Maybe 4 rounds is enough.
Now since we've dealt with the length->alpha formula, we can deal with the adaptivity part.
Logically, it doesn't make sense to use a slower-than-O(1) method to generate input for an O(1) method, so it must be something universal and minimalistic: something that will help us measure consistency in our data, yet something far away from statistics and close enough to topology.
There's one perfect entity that can help us, this is fractal efficiency. The way I define fractal efficiency can be checked at the very beginning of the post, what matters is that I add a square root to the formula that is not typically added.
As explained in the description of my metric QSFS, one of the reasons for SQRT-transformed values of fractal efficiency applied in moving window mode is because they start to closely resemble normal distribution, yet with support of (0, 1). Data with this interesting property (normally distributed yet with finite support) can be modeled with the beta distribution.
Another reason is, in infinitely expanding window mode, fractal efficiency of every time series that exhibits randomness tends to infinitely approach zero, sqrt-transform kind of partially neutralizes this effect.
Yet another reason is, the square root might better reflect the dimensional inefficiency or degree of fractal complexity, since it could balance the influence of extreme deviations from the net paths.
And finally, fractals exhibit power-law scaling -> measures like length, area, or volume scale in a non-linear way. Adding a square root acknowledges this intrinsic property, while connecting our metric with the nature of fractals.
---
I suspect that, given analogies and connections with other topics in geometry, topology, fractals and most importantly positive test results of the metric, it might be that the sqrt transform is the fundamental part of fractal efficiency that should be applied by default.
Now the last part of the ballet is to convert our fractal efficiency to length value. The part about inverse proportionality is obvious: high fractal efficiency aka high consistency -> lower window size, to utilize only the last data that contain brand new information that seems to be highly reliable since we have consistency in the first place.
The non-obvious part is now we need to neutralize the side effect created by previous sqrt transform: our length values are too low, and exponentiation is the perfect candidate to fix it since translating fractal efficiency into window sizes requires something non-linear to reflect the fractal dynamics. More importantly, using exp() was the last piece that let the metric shine, any other transformations & formulas alike I've tried always had some weird results on certain data.
That exp() in the len formula was the last piece that made it all work both on synthetic and on real data.

^^ a standalone script calculating optimal dynamic window size
Omg, THAT took time to write. Comment and/or text me if you need
...
"Versace Pip-Boy, I'm a young gun coming up with no bankroll"👻
∞
The HADES method is:
fit & forecast = a + b * (1 / alpha + T - 1)
T = 0 provides in-sample fit for the current datum, and T + n[1, inf] provides forecast for n datapoints.
y = input time series
a[t-1] = y, if no previous data exists
b[t-1] = 0, if no previous data exists
otherwise:
a = alpha * y + (1 - alpha) * a[t-1]
b = alpha * (a - a[t-1]) + (1 - alpha) * b[t-1]
alpha = 1 / sqrt(len * 4)
len = min(ceil(exp(1 / sig)), available data)
sig = sqrt(Absolute net change in y / Sum of absolute changes in y)
For the start datapoint when both numerator and denominator are zeros, we define 0 / 0 = 1
...
The same set of operations gets applied to the data first, then to resulting fit absolute residuals to build prediction interval, and finally to absolute forecasting errors (from one-point ahead forecast) to build forecasting interval:
prediction interval = data fit +- resoduals fit * k
forecasting interval = data opf +- errors fit * k
where k = multiplier regulating intervals width, and opf = one-point forecasts calculated at each time t
...
How-to:
0) Apply to your data where it makes sense, eg. tick data;
1) Use power transform to compensate for multiplicative behavior in case it's there;
2) If you have complete data or only the data you need, like the full history of adjusted close prices: go to the next step; otherwise, guided by your goal & analysis, adjust the 'start index' setting so the calculations will start from this point;
3) Use prediction interval to detect significant deviations from the process core & make decisions according to your strategy;
4) Use one-point forecast for nowcasting;
5) Use forecasting intervals to ~ understand where the next datapoints will emerge, given the data-generating process will stay the same & lack structural breaks.
I advise k = 1 or 1.5 or 4 depending on your goal, but 1 is the most natural one.
...
Why exponential smoothing at all? Why the double one? Why adaptive? Why not Holt's method?
1) It's O(1) algo complexity & recursive nature allows it to be applied in an online fashion to high-frequency streaming data; otherwise, it makes more sense to use other methods;
2) Double exponential smoothing ensures we are taking trends into account; also, in order to model more complex time series patterns such as seasonality, we need detrended data, and this method can be used to do it;
3) The goal of adaptivity is to eliminate the window size question, in cases where it doesn't make sense to use cumulative moving typical value;
4) Holt's method creates a certain interaction between level and trend components, so its results lack symmetry and similarity with other non-recursive methods such as quantile regression or linear regression. Instead, I decided to base my work on the original double exponential smoothing method published by Rob Brown in 1956, here's the original source, it's really hard to find it online. This cool dude is considered the one who've dropped exponential smoothing to open access for the first time🤘🏻
R&D log & explanations
If you wanna read this, you gotta know, you're taking a great responsability for this long journey, and it gonna be one hell of a trip hehe
Machine learning, apprentissage automatique, машинное обучение, digital signal processing, statistical learning, data mining, deep learning, etc., etc., etc.: all these are just artificial categories created by the local population of this wonderful world, but what really separates entities globally in the Universe is solution complexity / algorithmic complexity.
In order to get the game a lil better, it's gonna be useful to read the HTES script description first. Secondly, let me guide you through the whole R&D process.
To discover (not to invent) the fundamental universal principle of what exponential smoothing really IS, it required the review of the whole concept, understanding that many things don't add up and don't make much sense in currently available mainstream info, and building it all from the beginning while avoiding these very basic logical & implementation flaws.
Given a complete time t, and yet, always growing time series population that can't be logically separated into subpopulations, the very first question is, 'What amount of data do we need to utilize at time t?'. Two answers: 1 and all. You can't really gain much info from 1 datum, so go for the second answer: we need the whole dataset.
So, given the sequential & incremental nature of time series, the very first and basic thing we can do on the whole dataset is to calculate a cumulative <typical value>, such as cumulative moving mean or cumulative moving median.
Now we need to extend this logic to exponential smoothing, which doesn't use dataset length info directly, but all cool it can be done via a formula that quantifies the relationship between alpha (smoothing parameter) and length. The popular formulas used in mainstream are:
alpha = 1 / length
alpha = 2 / (length + 1)
The funny part starts when you realize that Cumulative Exponential Moving Averages with these 2 alpha formulas Exactly match Cumulative Moving Average and Cumulative (Linearly) Weighted Moving Average, and the same logic goes on:
alpha = 3 / (length + 1.5), matches Cumulative Weighted Moving Average with quadratic weights, and
alpha = 4 / (length + 2), matches Cumulative Weighted Moving Average with cubic weghts, and so on...
It all just cries in your shoulder that we need to discover another, native length->alpha formula that leverages the recursive nature of exponential smoothing, because otherwise, it doesn't make sense to use it at all, since the usual CMA and CMWA can be computed incrementally at O(1) algo complexity just as exponential smoothing.
From now on I will not mention 'cumulative' or 'linearly weighted / weighted' anymore, it's gonna be implied all the time unless stated otherwise.
What we can do is to approach the thing logically and model the response with a little help from synthetic data, a sine wave would suffice. Then we can think of relationships: Based on algo complexity from lower to higher, we have this sequence: exponential smoothing @ O(1) -> parametric statistics (mean) @ O(n) -> non-parametric statistics (50th percentile / median) @ O(n log n). Based on Initial response from slow to fast: mean -> median Based on convergence with the real expected value from slow to fast: mean (infinitely approaches it) -> median (gets it quite fast).
Based on these inputs, we need to discover such a length->alpha formula so the resulting fit will have the slowest initial response out of all 3, and have the slowest convergence with expected value out of all 3. In order to do it, we need to have some non-linear transformer in our formula (like a square root) and a couple of factors to modify the response the way we need. I ended up with this formula to meet all our requirements:
alpha = sqrt(1 / length * 2) / 2
which simplifies to:
alpha = 1 / sqrt(len * 8)
^^ as you can see on the screenshot; where the red line is median, the blue line is the mean, and the purple line is exponential smoothing with the formulas you've just seen, we've met all the requirements.
Now we just have to do the same procedure to discover the length->alpha formula but for double exponential smoothing, which models trends as well, not just level as in single exponential smoothing. For this comparison, we need to use linear regression and quantile regression instead of the mean and median.
Quantile regression requires a non-closed form solution to be solved that you can't really implement in Pine Script, but that's ok, so I made the tests using Python & sklearn:
paste.pics/SHHXB
^^ on this screenshot, you can see the same relationship as on the previous screenshot, but now between the responses of quantile regression & linear regression.
I followed the same logic as before for designing alpha for double exponential smoothing (also considered the initial overshoots, but that's a little detail), and ended up with this formula:
alpha = sqrt(1 / length) / 2
which simplifies to:
alpha = 1 / sqrt(len * 4)
Btw, given the pattern you see in the resulting formulas for single and double exponential smoothing, if you ever want to do triple (not Holt & Winters) exponential smoothing, you'll need len * 2, and just len * 1 for quadruple exponential smoothing. I hope that based on this sequence, you see the hint that Maybe 4 rounds is enough.
Now since we've dealt with the length->alpha formula, we can deal with the adaptivity part.
Logically, it doesn't make sense to use a slower-than-O(1) method to generate input for an O(1) method, so it must be something universal and minimalistic: something that will help us measure consistency in our data, yet something far away from statistics and close enough to topology.
There's one perfect entity that can help us, this is fractal efficiency. The way I define fractal efficiency can be checked at the very beginning of the post, what matters is that I add a square root to the formula that is not typically added.
As explained in the description of my metric QSFS, one of the reasons for SQRT-transformed values of fractal efficiency applied in moving window mode is because they start to closely resemble normal distribution, yet with support of (0, 1). Data with this interesting property (normally distributed yet with finite support) can be modeled with the beta distribution.
Another reason is, in infinitely expanding window mode, fractal efficiency of every time series that exhibits randomness tends to infinitely approach zero, sqrt-transform kind of partially neutralizes this effect.
Yet another reason is, the square root might better reflect the dimensional inefficiency or degree of fractal complexity, since it could balance the influence of extreme deviations from the net paths.
And finally, fractals exhibit power-law scaling -> measures like length, area, or volume scale in a non-linear way. Adding a square root acknowledges this intrinsic property, while connecting our metric with the nature of fractals.
---
I suspect that, given analogies and connections with other topics in geometry, topology, fractals and most importantly positive test results of the metric, it might be that the sqrt transform is the fundamental part of fractal efficiency that should be applied by default.
Now the last part of the ballet is to convert our fractal efficiency to length value. The part about inverse proportionality is obvious: high fractal efficiency aka high consistency -> lower window size, to utilize only the last data that contain brand new information that seems to be highly reliable since we have consistency in the first place.
The non-obvious part is now we need to neutralize the side effect created by previous sqrt transform: our length values are too low, and exponentiation is the perfect candidate to fix it since translating fractal efficiency into window sizes requires something non-linear to reflect the fractal dynamics. More importantly, using exp() was the last piece that let the metric shine, any other transformations & formulas alike I've tried always had some weird results on certain data.
That exp() in the len formula was the last piece that made it all work both on synthetic and on real data.
^^ a standalone script calculating optimal dynamic window size
Omg, THAT took time to write. Comment and/or text me if you need
...
"Versace Pip-Boy, I'm a young gun coming up with no bankroll"👻
∞
Script open-source
Dans l'esprit TradingView, le créateur de ce script l'a rendu open source afin que les traders puissent examiner et vérifier ses fonctionnalités. Bravo à l'auteur! Bien que vous puissiez l'utiliser gratuitement, n'oubliez pas que la republication du code est soumise à nos Règles.
Gor Dragongor
t.me/synchro1_channel
linkedin.com/company/synchro1
t.me/synchro1_channel
linkedin.com/company/synchro1
Clause de non-responsabilité
Les informations et publications ne sont pas destinées à être, et ne constituent pas, des conseils ou recommandations financiers, d'investissement, de trading ou autres fournis ou approuvés par TradingView. Pour en savoir plus, consultez les Conditions d'utilisation.
Script open-source
Dans l'esprit TradingView, le créateur de ce script l'a rendu open source afin que les traders puissent examiner et vérifier ses fonctionnalités. Bravo à l'auteur! Bien que vous puissiez l'utiliser gratuitement, n'oubliez pas que la republication du code est soumise à nos Règles.
Gor Dragongor
t.me/synchro1_channel
linkedin.com/company/synchro1
t.me/synchro1_channel
linkedin.com/company/synchro1
Clause de non-responsabilité
Les informations et publications ne sont pas destinées à être, et ne constituent pas, des conseils ou recommandations financiers, d'investissement, de trading ou autres fournis ou approuvés par TradingView. Pour en savoir plus, consultez les Conditions d'utilisation.