Traders AID / Adaptive Smoothing Line (use on 1-week TF)TradersAID – Adaptive Smoothing Line (use on 1-week TF)
1. Overview
TradersAID – Adaptive Smoothing Line is a trend-following overlay designed to bring structure to noisy markets — especially on the 1-week chart, where clarity is crucial.
Instead of using conventional moving averages, this tool applies a Kalman-inspired smoothing method that adapts to changing price behavior.
Originally used in fields like robotics and autonomous driving, this filtering concept helps track directional flow without overreacting to minor fluctuations — making it easier to identify sustained moves or exhaustion patterns.
2. What It Does
The line continuously adapts to current market conditions by filtering volatility and directional flow through an internal estimator logic.
Unlike laggy moving averages, it does not simply average past prices — it adjusts dynamically based on how price behaves.
Key behaviors include:
• Directional slope that reflects trend strength
• Increased sensitivity during acceleration phases
• Stabilized flattening during sideways periods
This makes the trend easier to follow without being distracted by short-term chop.
3. How to Use It
• Trend Interpretation:
Use the line’s angle to judge momentum. Steep slopes show conviction, while flattening may signal transition or fading strength.
• Support & Resistance Context:
During trending phases, the line often acts as dynamic support or resistance — especially when combined with other tools.
• Volatility Filtering:
In consolidation, the line becomes smoother, helping reduce noise and simplify your view of structure.
• Layering Tool:
Use it as a visual foundation beneath more reactive tools like TradersAID Warning Dots or Velocity Coloring to stay grounded in context.
4. Key Features
• Adaptive Behavior: Responds to both price and volatility
• Three Modes:
o Slow for structure clarity
o Regular for balanced responsiveness
o Fast for shorter-term context
• Overlay Design: Plots directly on price for seamless interpretation
• Minimalist Output: Clean, unobtrusive line — no clutter
5. Technical Basis (Why It’s Closed Source)
This tool uses a custom smoothing technique based on Kalman-inspired logic, tuned specifically for longer-term trend structure.
While not a full Kalman implementation, the core idea is drawn from systems that track state under uncertainty — offering stability without lagging behind price.
The algorithm adapts continuously to live market input, producing a smooth yet responsive curve that reflects trend direction and change in a visually intuitive way.
As this smoothing mechanism is not available in open-source scripts and is part of a broader proprietary system, the code remains closed to protect its originality and performance edge.
6. Settings
• Mode Selection: Fast / Regular / Slow
• Styling Controls: Color, line width, smoothing curve
• Frame Lock:
✅ This tool is designed to work exclusively on the 1-week timeframe.
7. Disclaimer
This script is for educational and informational purposes only. It does not provide financial advice or generate trading signals. Use with your own judgment and supporting tools.
Estimation
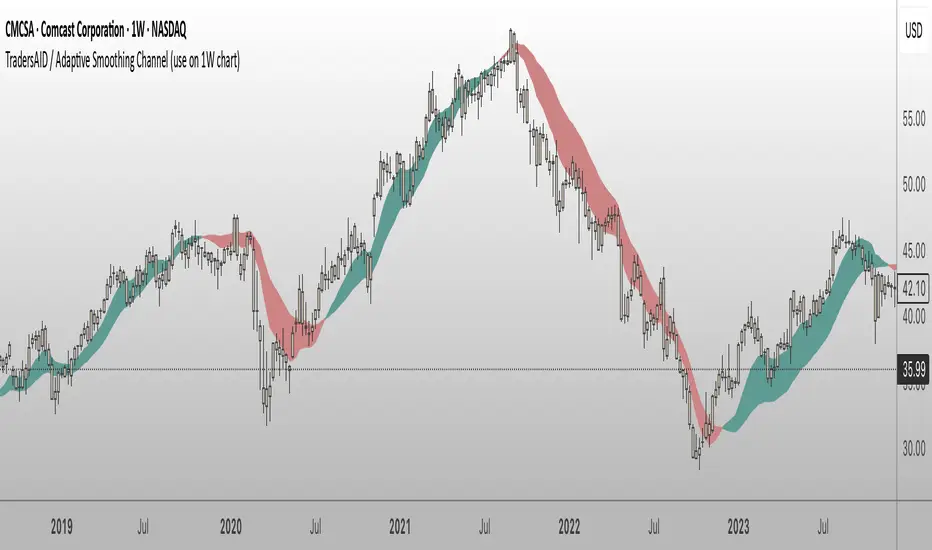
TradersAID / Adaptive Smoothing Channel (use on 1W chart)TradersAID – Adaptive Smoothing Channel (use on 1-Week chart)
Overview
TradersAID – Adaptive Smoothing Channel is a two-line price overlay designed to help traders interpret trend structure and shifting momentum zones on the 1-week chart only.
Unlike traditional moving averages or fixed smoothing methods, this tool uses an adaptive approach inspired by Kalman filtering — a concept widely used in robotics and control systems to track signals in noisy environments. Applied to price, this allows the band to adapt to directional flow and volatility while filtering out distracting short-term fluctuations.
1.What It Does
This tool builds a dynamic corridor around price using:
• A faster line that follows near-term directional movement
• A slower line that anchors broader market structure
Together, they form a responsive band that:
• Tilts with trend direction (via slope)
• Expands or contracts with volatility
• Fills the space between to show directional rhythm
It’s especially useful for observing how price moves within sustained trends or compression zones, helping traders visually interpret market structure with more clarity.
2. How to Use It
• Trend Structure:
Follow the slope of the band to understand overall direction. A narrowing band may indicate consolidation; a widening band may reflect strong follow-through.
• Momentum Compression Zones:
Watch for tightening distance between the lines — this may signal the market is preparing for a structural transition or breakout.
• Clarity Layer:
Overlay this tool with others (e.g. TradersAID Warning Dots) to reduce noise and improve decision context.
3. Key Features
• Dual Adaptive Lines: One fast, one slow — capturing different time dynamics
• Shaded Fill Zone: Highlights directional bias and rhythm
• 3 Reaction Modes: Slow / Regular / Fast for different sensitivities
• Overlay Style: Plots directly on price
• Minimalist Layout: Clean visual language
4. Technical Basis (Why It’s Closed Source)
This tool is based on a custom smoothing logic inspired by Kalman filtering, adapted specifically for charting market structure.
While it does not replicate a full Kalman system, it borrows key principles: dynamically adjusting to noisy input while maintaining structural clarity.
The algorithm was developed internally to provide a visual layer that integrates into the broader TradersAID analysis system — offering something distinct from public indicators. Its behavior, flexibility, and integration were designed to serve advanced structural analysis, and as such, the script is closed to protect proprietary logic and intellectual property.
5. Settings
• Mode Selector: Fast / Regular / Slow
• Color Fill Toggle & Styling
• Frame Lock:
✅ This script is built to work exclusively on the 1-week timeframe.
6. Disclaimer
This tool is for educational and informational purposes only. It does not offer financial advice or generate trading signals. Always use with your own strategy and discretion.
FunctionSurvivalEstimationLibrary "FunctionSurvivalEstimation"
The Survival Estimation function, also known as Kaplan-Meier estimation or product-limit method, is a statistical technique used to estimate the survival probability of an individual over time. It's commonly used in medical research and epidemiology to analyze the survival rates of patients with different treatments, diseases, or risk factors.
What does it do?
The Survival Estimation function takes into account censored observations (i.e., individuals who are still alive at a certain point) and calculates the probability that an individual will survive beyond a specific time period. It's particularly useful when dealing with right-censoring, where some subjects are lost to follow-up or have not experienced the event of interest by the end of the study.
Interpretation
The Survival Estimation function provides a plot of the estimated survival probability over time, which can be used to:
1. Compare survival rates between different groups (e.g., treatment arms)
2. Identify patterns in the data that may indicate differences in mortality or disease progression
3. Make predictions about future outcomes based on historical data
4. In a trading context it may be used to ascertain the survival ratios of trading under specific conditions.
Reference:
www.global-developments.org
"Beyond GDP" ~ www.aeaweb.org
en.wikipedia.org
www.kdnuggets.com
survival_probability(alive_at_age, initial_alive)
Kaplan-Meier Survival Estimator.
Parameters:
alive_at_age (int) : The number of subjects still alive at a age.
initial_alive (int) : The Total number of initial subjects.
Returns: The probability that a subject lives longer than a certain age.
utility(c, l)
Captures the utility value from consumption and leisure.
Parameters:
c (float) : Consumption.
l (float) : Leisure.
Returns: Utility value from consumption and leisure.
welfare_utility(age, b, u, s)
Calculate the welfare utility value based age, basic needs and social interaction.
Parameters:
age (int) : Age of the subject.
b (float) : Value representing basic needs (food, shelter..).
u (float) : Value representing overall well-being and happiness.
s (float) : Value representing social interaction and connection with others.
Returns: Welfare utility value.
expected_lifetime_welfare(beta, consumption, leisure, alive_data, expectation)
Calculates the expected lifetime welfare of an individual based on their consumption, leisure, and survival probability over time.
Parameters:
beta (float) : Discount factor.
consumption (array) : List of consumption values at each step of the subjects life.
leisure (array) : List of leisure values at each step of the subjects life.
alive_data (array) : List of subjects alive at each age, the first element is the total or initial number of subjects.
expectation (float) : Optional, `defaut=1.0`. Expectation or weight given to this calculation.
Returns: Expected lifetime welfare value.

Static price-range projection by symbolThis indicator shows you a predefined range to the right of the last candle of your chart. This range is custom and can be changed for a handful of symbols that you can choose. This scale will help you determining if the market is providing a reasonable range before you enter a trade or if the market isn't actually moving as much as you might think. This is particularly useful if you are into scalping and have to consider commission or spread in your trades.
Since all symbols have different price ranges in which they move this indicator doesn't make sense to just have "a one size fits all" approach. That's why you can choose up to 6 symbols and set the range that you want to have shown for each when you pull it up on the chart. Using my default values that means for when the NQ (Nasdaq future) is on the chart you will see a range of 20 handles projected. When you change the the ES (S&P500 future) you will instead see 5 handles. While the number is different that is somewhat of an equal move in both symbols.
There also is an option to set a default price range for all other symbols that are not selected if it is needed. However the display of the scale on anything else than the 6 selected symbols can also be turned off.
There are options provided on how exactly you want to indicator to determine if the chart symbol matches one of the selected symbols.
You can enable it to make sure the exchange/broker is the exact same as selected.
It can check for only the symbol root to match the selection. Specifically for futures this means that while ES1! might be selected, anything ES (ES1!, ES2!, ESH2025, ESM2025, ESM2022, ...) will be a match to the selection)
On the painted scale it is possible to not just show this range extended into each direction once. Per default you will have 3 segments of it in each direction. This can be reduced to just 1 or increased.
If you chose a high number of segments or a large range make sure to use the "Scale price chart only" option on your chart scale to not have the symbols price candles squished together by the charts auto scaling.
And last but not least the indicator options provide some possibilities to change the appearance of the printed price range scale in case you disagree with my design.

Polyphase MACD (PMACD)The Polyphase MACD (PMACD) uses polyphase decimation to create a continuous estimate of higher timeframe MACD behavior. The number of phases represents the timeframe multiplier - for example, 3 phases approximates a 3x higher timeframe.
Traditional higher timeframe MACD indicators update only when each higher timeframe bar completes, creating stepped signals that can miss intermediate price action. The PMACD addresses this by maintaining multiple phase-shifted MACD calculations and combining them with appropriate anti-aliasing filters. This approach eliminates the discrete jumps typically seen in higher timeframe indicators, though the resulting signal may sometimes deviate from the true higher timeframe values due to its estimative nature.
The indicator processes price data through parallel phase calculations, each analyzing a different time-offset subset of the data. These phases are filtered and combined to prevent aliasing artifacts that occur in simple timeframe conversions. The result is a smooth, continuous signal that begins providing meaningful values immediately, without requiring a warm-up period of higher timeframe bars.
The PMACD maintains the standard MACD components - the MACD line (fast MA - slow MA), signal line, and histogram - while providing a more continuous view of higher timeframe momentum. Users can select between EMA and SMA calculations for both the oscillator and signal components, with all calculations benefiting from the same polyphase processing technique.
Extreme Fundamental PricesExtreme Fundamental Prices is developed for Stock Markets to see the optimum, estimated and extreme estimated prices of any stocks on any markets. It works globally. Every country has different inflation, interest and deposit interest rates. The indicator consider these difference and it adopts itself automatically for chosen stock. Only the "Deposit Interest Rate" is manual because tradingview does not support this value for every country or value is wrong. If you know the deposit interest rate of your country enter the value manually. This is priority. Otherwise switch to "Interest Rate" on the menu. However the Optimum P/E line is not developed to work perfectly with this option. The Extreme Fundamental Prices indicator consists three lines which are,
-Optimum P/E
-Estimated 1Y Price
-Extreme Estimated 1Y Price
Optimum P/E line consists the financial data of chosen stock and economic data of country; which are financials of the stocks, inflation rate, deposit interest rate and interest rate(if "Interest Rate" option chosen).
Estimated 1Y Price line consists the financial data of chosen stock.
Extreme Estimated 1Y Price line consists the financial data of chosen stock.
This indicator does not tell you to buy or sell the stock. If stock price above these lines, the stock is fundamentally overpriced. If stock price below these lines, the stock is not fundamentally overpriced. Logically, price can tend to meet these lines.
For Instance, default value 33.00 is the current Deposit Interest Rate of Turkey. I am using this rate to look stocks on BIST. If you are looking on NASDAQ, just simply enter the deposit interest rate value of USA, looking for DAX enter the Euro Zone deposit interest rate.

Faytterro Oscillatorwhat is Faytterro oscillator?
An oscillator that perfectly identifies overbought and oversold zones.
what it does?
this places the price between 0 and 100 perfectly but with a little delay. To eliminate this delay, it predicts the price to come, and the indicator becomes clearer as the probability of its prediction increases.
how it does it?
This indicator is obtained with "faytterro bands", another indicator I designed. For more information about faytterro bands:
A kind of stochastic function is applied to the faytterro bands indicator, and then another transformation formula that I have designed and explained in detail in the link above is applied. These formulas are also applied again to calculate the prediction parts.
how to use it?
Use this indicator to see past overbought and oversold zones and to see future ones.
The input named source is used to change the source of the indicator.
The length serves to change the signal frequency of the indicator.

Profit EstimateLibrary "profitestimate"
Simple profit Estimatr. Engages when Position != 0
and holds until posittion is na/0...
if position changes sizes, it will update automatically and adjust.
it has an input for comission to estmate exit fees
update_avgprice(_sizewas, _delta, _pricewas, _newprice)
Get a new Average position Price
Parameters:
_sizewas : (float) the position prior
_delta : (float) the order amount
_pricewas : (float) the prior price
_newprice : (float) the price of order
Returns: New Avg Price
amount(_position, _close, _commission, _leverage, _fullqty)
Position Net Profit Net Commission, automatic on/off if position != 0
Parameters:
_position : (float) position size (total or margin size)
_close
_commission : (float) % where (0.1 = 0.1%)
_leverage : (float) optional if leveraged, default 1x
_fullqty : (bool) if position entered is tottal trade size default is margin qty (1/lev)
Returns: quote value of profit
percent(_position, _close, _commission, _leverage, _fullqty)
Position Net Profit, automatic on/off if position != 0
Parameters:
_position : (float) position size (total or margin size)
_close
_commission : (float) % where (0.1 = 0.1%)
_leverage : (float) optional if leveraged, default 1x
_fullqty : (bool) if position entered is tottal trade size, default is margin qty (1/lev)
Returns: percentage profit (1% = 1)
Quantitative Kernel DelimiterQuantitative Kernel Delimiter QKD - aka "Fire and ICE" - is a six-level multiple Kernel regression estimator with cross-timeframe semi-coordinated delimiters (bands) enabled by mathematical validation to our own Kernel regression code with historical Kernel formulas having custom variable bandwidths , mults , and window width – all achieving an advanced alerting system and directional price-action pointers for Novice, Intermediate and Advanced Traders within the TradingView Graphical User Interface.
In the course of our work, we have found that such six delimiters are ideal for generating signals of varying strengths.
99.9% of observations should be in our delimiters' range:
Kernel regression is a nonparametric smoothing method for data modeling.
Kernel regression of statistics was derived independently by Nadaraya and Watson in 1964 with a mathematical foundation given by Parzen’s earlier work on kernel density estimation.
If you are interested in reading more about the mathematical basis of this method from which our code is derived, you can follow these scholarly links:
Expert Trading Systems: Modeling Financial Markets with Kernel Regression
Estimation of the bandwidth parameter in Nadaraya-Watson
Adaptive optimal kernel density estimation for directional data
How kernel regression differs from the other Moving Averages?
In most MA's data points in the specified lookback window are weighted equally. In contrast, the Gaussian Kernel function used in this indicator assigns a higher weight to data points that are closer to the current point. This means that the indicator will react more quickly to changes in the market.
Regression method from which our code is derived is a widely known formula that is laid out in many sources, we used this source:
Kernel regression estimation
Kernel
During the regression counting process, a `kernel function` is used, which is traditionally chosen from a wide variety of symmetric functions.
In this indicator, we use the Gaussian density of statistics as the kernel function.
The Gaussian Kernel is one of the most commonly used Kernel functions and is used extensively in many Machine Learning algorithms due to its general applicability across a wide variety of datasets.
The kernel regression averages all the data contained within the range of the kernel function.
The effective range of the kernel function is defined by its window width .
Kernel Delimiters (Bands / Levels)
This indicator has 6 tailored price range* delimiters:
Cold / Fire - the furthest delimiters. In a range market when the price enters the cold/fire zones it is assumed that it has deviated strongly from the average and there is a high probability that it will immediately return to the average, or at least into the underlying zone, also in a trending market it signals a change in trend.
ALERT: the indicator performs best during relatively sideways price action within an established range. The trader must check higher timeframes during hits on the extreme Cold or Fire delimiter bands as a break in the lower, or even higher timeframe price range may result in a need to reset the regression calculation once price velocity calms down after a major move allowing the indicator to best function again. The reset will be done automatically by the indicator’s code. The indicator is not intended for use with unusually aggressive pricing behavior. Always beware of extreme market conditions. The indicator is intended as an ordinary range trading tool.
Gold / Green - we call it the middle ground / golden mean / happy medium zone. When the price comes out here but the momentum is not enough to get to the higher zone we consider it a good signal.
Pro - most often we receive signals in this area. We call it the professional zone because it is literally the zone for professional traders who know what they are dealing with.
*NOTE: the indicator is intended to be used as a range trading tool, and does not protect against total BREAKS from one Range to a new Range, wherein the bands reset for the trader.
Alerts / Labels
We have spent a lot of time implementing and testing signal labels* and alerts**.
Now you have access to an advanced alert system.
*NOTE: DUE TO the ongoing regression calculations performed by our code, the trader will note that a label may change color at a later point in time, or even soon after the hit on the quantitative delimiter band in question. This is a process that was reviewed and is favored to achieve visual clarity over historical accuracy for the trader. Real-time trading hits of price line to band, along with alerts generated, remain accurate. We look forward to receiving feedback on this issue from the end users. Additional revisions by our team on this matter are anticipated if a harmony between visual clarity and historical accuracy is not satisfied.
**NOTE: Smaller and especially micro timeframes will result in more repeated alerts given the tight proximity with price vis-à-vis the quantitative delimiter. Larger timeframes tend to eliminate any issue with repeated alerts aside from obvious re-contacting of the quantitative delimiter by the active price line.
You can turn off alerts you don't need in the indicator settings.
All alerts are set with one click.
Themes
Different people like different things, which is why we decided to make several visual design themes so you can choose what suits you.
Themes will continue to evolve over time.
Pro Theme:
Modern Theme:
How to remove colored text labels next to price scale to maximize screen space on mobile:
Go to General Chart Settings :
Click on “SCALES”
Un select “Indicators and financial name.”
Dynamic Mode
Projection of Indicator bands on history is subject to repainting due to its regressive calculation nature. Be cautious: old signals are drawn once at the first loading of the chart and by default (to speed up the start-up time of the indicator) correspond to the current regression levels. All labels remain in their places as the chart progresses. Also new, real-time labels appear on the chart, and do not disappear. In order to display the old signals on the chart as they were at the time of their appearance, uncheck the "History labels transition" in the indicator settings (it may increase the initial loading time of the chart but will give you an opportunity to check the alerts you received before and may also be useful for visual backtesting).
Because of the very nature of modeling financial markets (i.e., thousands of data records and perhaps hundreds of candidate predictors), the need for computational speed is paramount.
The use of kernel regression in data modeling for the types of problems associated with financial markets requires careful consideration of computational time.
Once we acknowledge that the order of the data is important, then the choice of the learning-data-set becomes crucial. The time dimension introduces another level of complexity to the analysis: how much importance do we attach to recent data records as opposed to earlier records? Is there a simple way to take this effect into consideration? Common sense leads us to the basic conclusion that if we are to predict a value of Y at a given time, we should only use learning data from an earlier time. But this procedure tends to be overly restrictive. This problem has a simple solution: All that one must do is to make the learning data set dynamic . In other words, once a record has been tested, it is then available for updating the learning data set prior to testing the next record. The analyst can allow the learning data set to grow, or, alternatively, for each record added, the earliest remaining record in the learning set can be discarded. These two alternatives have led us to the necessity of using moving window option and adding a disclaimer that dynamic mode is enabled.
This indicator will be updated frequently based on community feedback see the Author’s instructions below to get instant access
―――――――――――――――――――――
Liability Disclaimer
Never fully rely on one indicator as you trade. Successful trading may require an orchestral mindset and harmonіc blend of trading tools, know-how, and devices. VIP Trader . com is not responsible for any damages or losses incurred by use or misused of this indicator. Neither this description above, nor the indicator, is intended to be used as financial advisory tool, nor to be used without proper education or training in the field of trading.
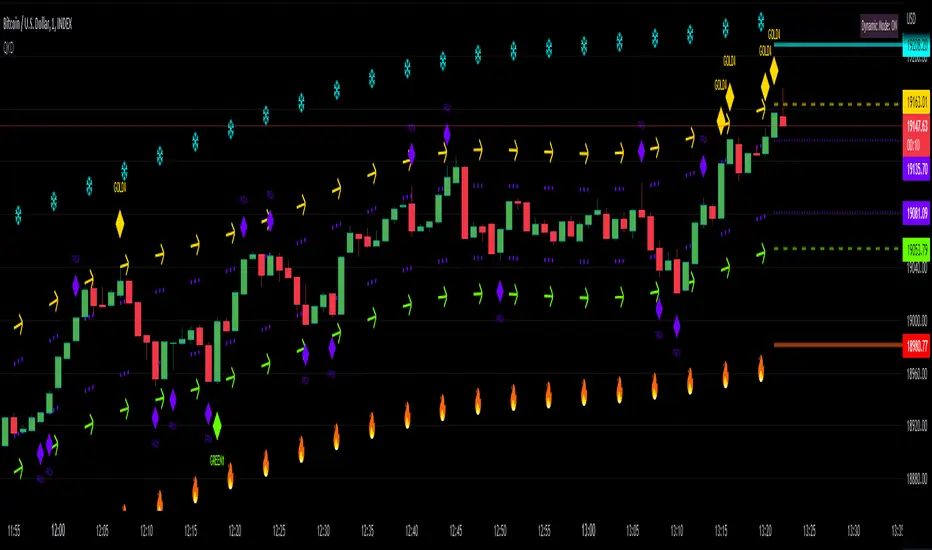
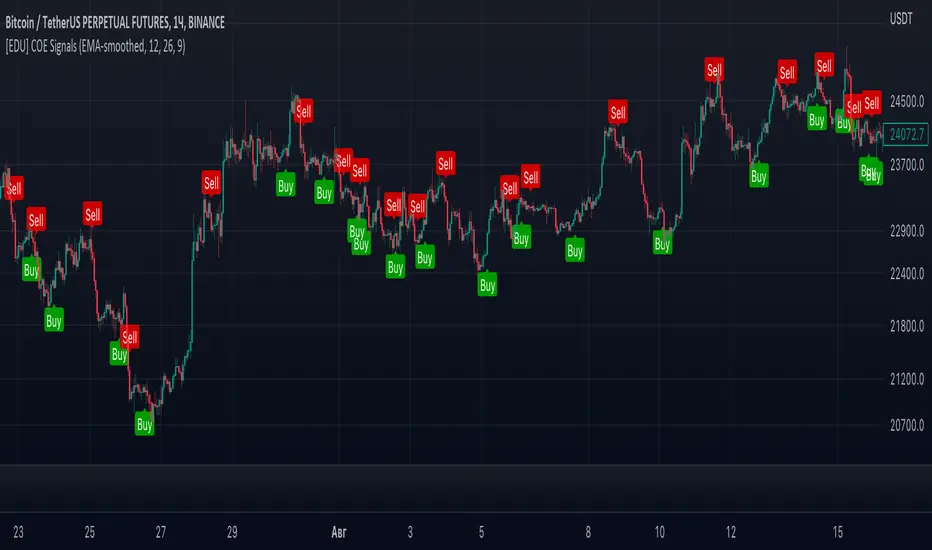
[EDU] Close Open Estimation Signals (COE Signals)EN:
Close Open Estimation ( aka COE ) is a very simple swing-trading indicator based on even simpler idea. This indicator is from my educational series, which means that I just want to share with another way to look at the market in order to broaden your knowledge .
Idea :
Let's take n previous bars and make a sum a of close - open -values of each bar. Knowledgeable of you may already see the similarity to RSI calculation idea . Now let's plot this sum and see what we have now.
We can see, that whenever COE crosses over 0-level, uptrend begins, and if COE crosses under 0-level, downtrend begins. The speed of such signals can be adjusted by changing lookback period: the lower the lookback, the faster signals you get, but high-quality ones can be obtained only via not-so-fast lookback as when the market is consolidating or volatility is to high, there can be many garbage signals, like 95+% of other indicators have.
Let's explore more and calculate volatility of COE(v_coe in the code): current COE - previous CEO .
Now it appears that when v_coe crosses over 0-level, it's a signal, that this is a new low and soon the uptrend will follow. Analogically for crossing under 0-level .
I guess now you understood what these all are about: COE crossings show global trend signals , while Volatility COE ( v_coe or VCOE ) crossings show reversal points .
For signals I further calculated volatility of VCOE(VVCOE) and then volatility of VVCOE(VVVCOE). Why? Because for me they seem to be more accurate, but you are welcome to experiment and figure best setups for yourself and by yourself, I just share my opinion and experience .
COE can be helpful only in high liquidity markets with good trend or wide sideways .
If you want to experiment with COE, just copy the code and play with it. Curious of you will probably find it helpful eventhough the idea is way too simple.
By it's perfomance COE can probably beat QQE at open price settings.
(use open of the price at indicator to get zero repaint! )
Examples :
If you any questions, feel free to DM me or leave comments.
Good luck and take your profits!
- Fyodor Tarasenko
RU:
Close Open Estimation ( aka COE ) — это очень простой индикатор свинг-трейдинга, основанный на еще более простой идее. Этот индикатор из моей образовательной серии, а это значит, что я просто хочу поделиться с другим взглядом на рынок , чтобы расширить ваши знания .
Идея :
Возьмем n предыдущих баров и составим сумму a из close - open -значений каждого бара. Знающие люди могут уже заметить сходство с идеей расчета RSI . Теперь давайте построим эту сумму и посмотрим, что у нас сейчас есть.
Мы видим, что всякий раз, когда COE пересекает выше 0-уровня, начинается восходящий тренд , а если COE пересекает ниже 0-уровня, начинается нисходящий тренд. Скорость таких сигналов можно регулировать изменением ретроспективы: чем меньше ретроспектива, тем быстрее вы получаете сигналы, но качественные можно получить только через не- такой быстрый взгляд назад, как когда рынок консолидируется или волатильность слишком высока, может быть много мусорных сигналов, как у 95+% других индикаторов.
Давайте рассмотрим больше и рассчитаем волатильность COE(v_coe в коде): текущий COE - предыдущий CEO .
Теперь кажется, что когда v_coe пересекает уровень 0, это сигнал о том, что это новый минимум и вскоре последует восходящий тренд . Аналогично для пересечения под 0-уровнем .
Думаю, теперь вы поняли, о чем все это: COE пересечения показывают глобальные сигналы тренда , а пересечения Volatility COE ( v_coe или VCOE ) показывают точки разворота .
Для сигналов я дополнительно рассчитал волатильность VCOE(VVCOE), а затем волатильность VVCOE(VVVCOE). Почему? Потому что для меня они кажутся более точными, но вы можете поэкспериментировать и подобрать оптимальные настройки для себя и для себя, я просто делюсь своим мнением и опытом .
COE может быть полезен только на рынках с высокой ликвидностью и хорошим трендом или широким боковиком .
Если вы хотите поэкспериментировать с COE, просто скопируйте код и поэкспериментируйте с ним. Любознательные из вас, вероятно, сочтут это полезным, хотя идея слишком проста.
По своей результативности СОЕ может составить конкуренцию широко известному QQE, используя open цены.
(используйте open цены на индикаторе, чтобы получить нулевую перерисовку! )
Примеры :
Если у вас есть вопросы, пишите мне в личные сообщения или оставляйте комментарии.
Удачи и профита всем!
- Федор Тарасенко
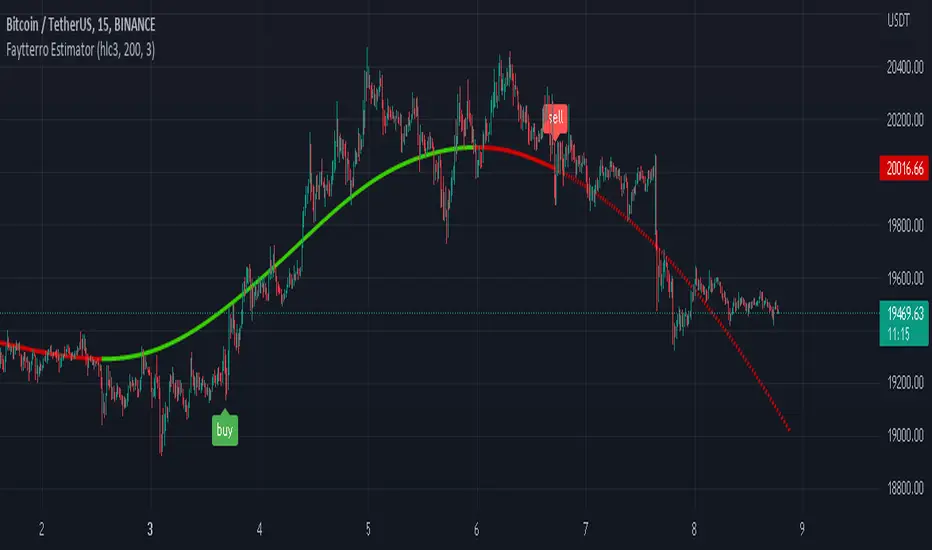
Faytterro EstimatorWhat is Faytterro Estimator?
This indicator is an advanced moving average.
What it does?
This indicator is both a moving average and at the same time, it predicts the future values that the price may take based on the values it has taken before.
How it does it?
takes the weighted average of data of the selected length (reducing the weight from the middle to the ends). then draws a parabola through the last three values, creating a predicted line.
How to use it?
it is simple to use. You can use it both as a regression to review past prices, and to predict the future value of a price. uptrends are in green and downtrends are in red. color change indicates a possible trend change.
Nearest Neighbor Extrapolation of Price [Loxx]I wasn't going to post this because I don't like how this calculates by puling in the Open price, but I'm posting it anyway. This does work in it's current form but there is a. better way to do this. I'll revisit this in the future.
Anyway...
The k-Nearest Neighbor algorithm (k-NN) searches for k past patterns (neighbors) that are most similar to the current pattern and computes the future prices based on weighted voting of those neighbors. This indicator finds only one nearest neighbor. So, in essence, it is a 1-NN algorithm. It uses the Pearson correlation coefficient between the current pattern and all past patterns as the measure of distance between them. Also, this version of the nearest neighbor indicator gives larger weights to most recent prices while searching for the closest pattern in the past. It uses a weighted correlation coefficient, whose weight decays linearly from newer to older prices within a price pattern.
This indicator also includes an error window that shows whether the calculation is valid. If it's green and says "Passed", then the calculation is valid, otherwise it'll show a red background and and error message.
Inputs
Npast - number of past bars in a pattern;
Nfut -number of future bars in a pattern (must be < Npast).
lastbar - How many bars back to start forecast? Useful to show past prediction accuracy
barsbark - This prevents Pine from trying to calculate on all past bars
Related indicators
Hodrick-Prescott Extrapolation of Price
Itakura-Saito Autoregressive Extrapolation of Price
Helme-Nikias Weighted Burg AR-SE Extra. of Price
Weighted Burg AR Spectral Estimate Extrapolation of Price
Levinson-Durbin Autocorrelation Extrapolation of Price
Fourier Extrapolator of Price w/ Projection Forecast

test - delta distributiona test case for the KDE function on price delta.
the KDE function can be used to quickly check or confirm edge cases of the trading systems conditionals.

Function - Kernel Density Estimation (KDE)"In statistics, kernel density estimation (KDE) is a non-parametric way to estimate the probability density function of a random variable."
from wikipedia.com
KDE function with optional kernel:
Uniform
Triangle
Epanechnikov
Quartic
Triweight
Gaussian
Cosinus
Republishing due to change of function.
deprecated script:

KDE-Gaussian"In statistics, kernel density estimation (KDE) is a non-parametric way to estimate the probability density function of a random variable."
from wikipedia.com

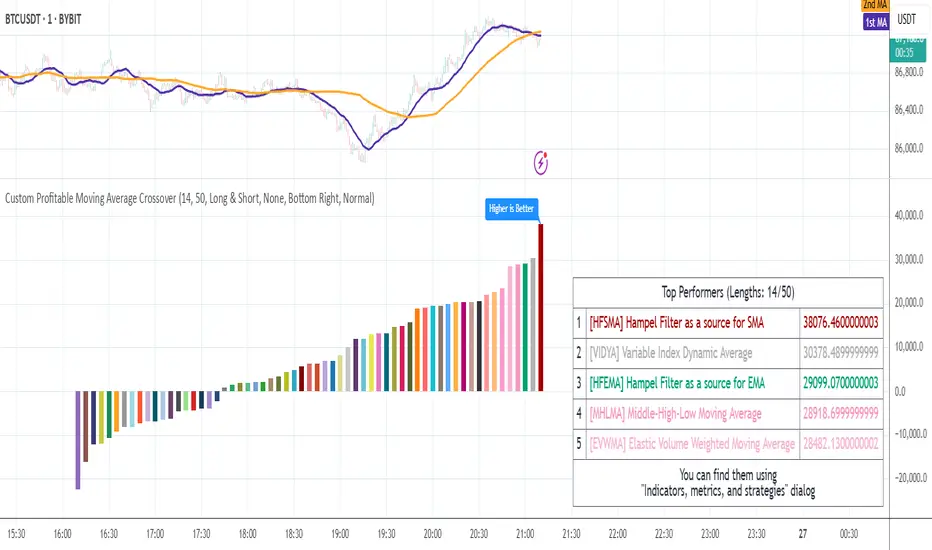
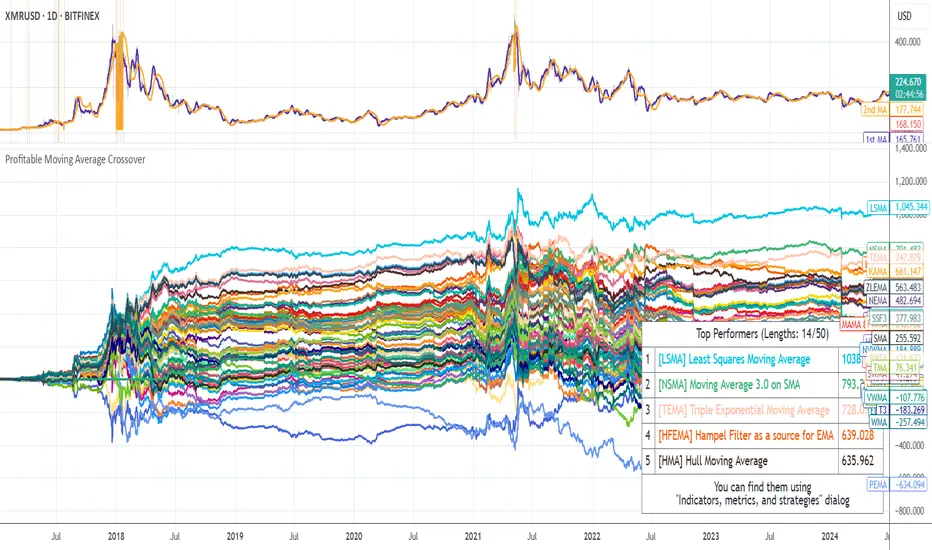
Compact Profitable Moving Average CrossoverHello friends,
I'm pleased to introduce this advanced evolution of the original Profitable Moving Average Crossover tool. This version offers complete control over the analysis range and delivers detailed real-time profitability metrics for every moving average crossover type directly on your chart.
🛠 How It Works
The script evaluates 61 moving average crossover systems across a customizable date range , allowing you to focus on specific historical windows for optimization or validation. It calculates each crossover's net profit performance and automatically ranks all results, displaying the top 5 performers in a summary table. Results are visualized through a color-coded column chart, making it easy to identify which crossover types have historically delivered the strongest outcomes.
🔥 Key Features
Pine Script V6 — built on the latest and most efficient version
Tests 61 moving average types , including those developed by Jurik, Kaufman, Ehlers, Apirine, and others
Custom Backtest Window — analyze any date range with start and end parameters
Automatic Results Table — displays the top 5 crossovers ranked by profit
Color-Coded Chart — quick visual identification of performance by crossover type
Sorted column chart for clear visual comparison of profit metrics
Fully compatible with all symbols, timeframes, and market types
NOTE: Results will vary across different tickers and timeframes. Seeing strong performance in one preview does not imply similar profitability elsewhere — this variability is normal due to differing market structures.
NOTE 2: You can experiment with the tool independently or request a full study, in which case I'll share a spreadsheet of all backtest results with you.
👋 Good luck and happy trading!
Script payant
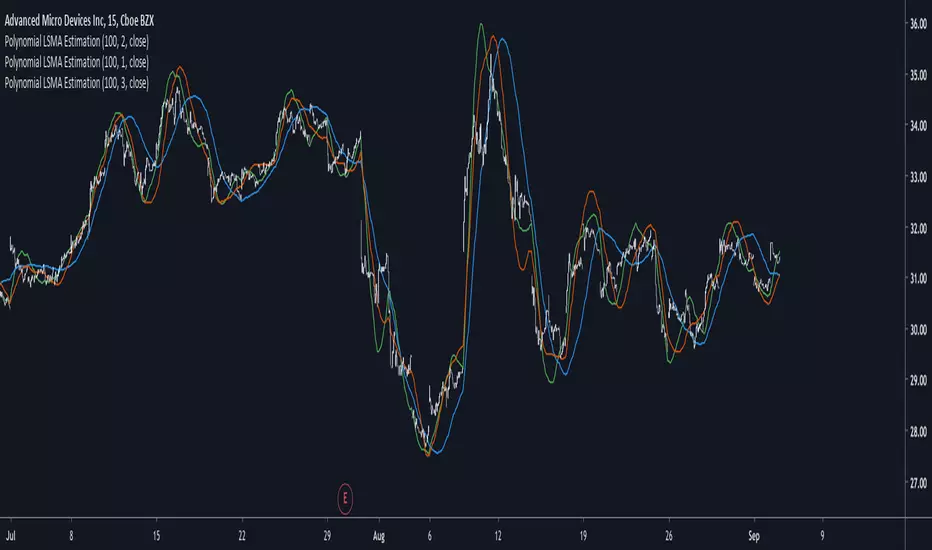
Polynomial LSMA Estimation - Estimating An LSMA Of Any DegreeIntroduction
It was one of my most requested post, so here you have it, today i present a way to estimate an LSMA of any degree by using a kernel based on a sine wave series, note that this is originally a paper that i posted that you can find here figshare.com , in the paper you will be able to find the frequency response of the filter as well as both python and pinescript code.
The least squares moving average or LSMA is a filter that best fit a polynomial function through the price by using the method of least squares, by default the LSMA best fit a line through the input by using the following formula : ax + b where x is often a linear series 1,2,3...etc and a/b are parameters, the LSMA is made by finding a and b such that their values minimize the sum of squares between the lsma and the input.
Now a LSMA of 2nd degree (quadratic) is in the form of ax^2 + bx + c , although the first order LSMA is not hard to make the 2nd order one is way more heavy in term of codes since we must find optimal values for a , b and c , therefore we may want to find alternatives if the goal is simply data smoothing.
Estimation By Convolution
The LSMA is a FIR filter which posses various characteristics, the impulse response of an LSMA of degree n is a polynomial of the same degree, and its step response is a polynomial of degree n+1, estimating those step response is done by the described sine wave series :
f(x) =>
sum = 0.
b = 0.
pi = atan(1)*4
a = x*x
for i = 1 to d
b := 1/i * sin(x*i*pi)
sum := sum + b
pol = a + iff(d == 0,0,sum)
which is simple the sum of multiple sine waves of different frequency and amplitude + the square of a linear function. We then differentiate this result and apply convolution.
The Indicator
length control the filter period while degree control the degree of the filter, higher degree's create better fit with the input as seen below :
Now lets compare our estimate with actual LSMA's, below a lsma in blue and our estimate in orange of both degree 1 and period 100 :
Below a LSMA of degree 2 (quadratic) and our estimate with degree 2 with both period 100 :
It can be seen that the estimate is doing a pretty decent job.
Now we can't make comparisons with higher degrees of lsma's but thats not a real necessity.
Conclusion
This indicator wasn't intended as a direct estimate of the lsma but it was originally based on the estimation of polynomials using sine wave series, which led to the proposed filter showcased in the article. So i think we can agree that this is not a bad estimate although i could have showcased more statistics but thats to many work, but its not that interesting to use higher degree's anyways so sticking with degree 1, 2 and 3 might be for the best.
Hope you like and thanks for reading !
Japanese Correlation CoefficientIntroduction
This indicator was asked and named by a trading meetup participant in Sevilla. The original question was "How to estimate the correlation between the price and a line as easy as possible", a question who got little attention. I previously proposed a correlation estimate using a modification of the standard score (see at the end of the post) for the estimation of a Savitzky-Golay moving average (LSMA) of order 1, however something faster could maybe be done and this is why i accepted the challenge.
Japanese Correlation
Correlation is defined as the linear relationship between two variables x and y , if x and y follow the same direction then the correlation increase else decrease. The correlation coefficient is always equal or below 1 and equal or above -1, it also have to be taken into account that this coefficient is quite smooth. Smoothing is not a problem, scaling however require more attention, high price > closing price > low price, therefore scaling can be done. First we smooth the closing/high/low price with a simple moving average of period p/2 , then we take the difference of the smoothed close with the smoothed close p/2 bars back, this result is then divided by the difference between the highest smoothed high's with the lowest smoothed low's over period p/2 .
Since we use information provided by candlesticks (close/high/low) i have been asked to publish this estimator with the name Japanese correlation coefficient , this name don't imply the use of data from Japanese markets, "Japanese" is used because of the candlestick method coming from Japan.
Comparison
I compare this estimation with the correlation coefficient provided in pinescript by the correlation function.
The estimation in orange with the original correlation coefficient using n as independent variable in blue with both length = 50.
comparison with length = 200.
Conclusion
I have shown that it is possible to roughly estimate the correlation coefficient between price and a linear function by using different price information. Correlation can be further estimated by using homogeneous bridge OHLC volatility estimators thus making able the use of different independent variables. I really hope you like this indicator and thanks to the meetup participant asking the question, i had a lot of fun making the indicator.
An alternative method

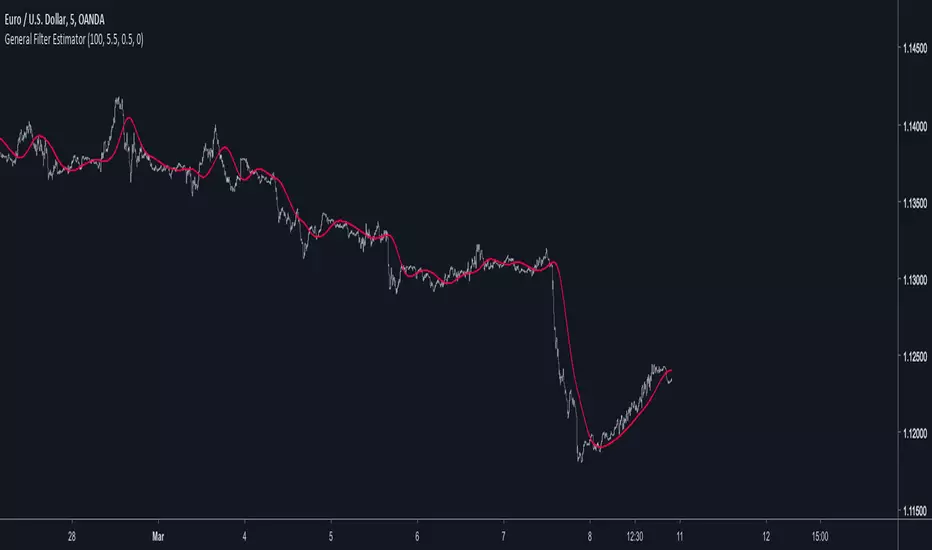
General Filter Estimator-An Experiment on Estimating EverythingIntroduction
The last indicators i posted where about estimating the least squares moving average, the task of estimating a filter is a funny one because its always a challenge and it require to be really creative. After the last publication of the 1LC-LSMA , who estimate the lsma with 1 line of code and only 3 functions i felt like i could maybe make something more flexible and less complex with the ability to approximate any filter output. Its possible, but the methods to do so are not something that pinescript can do, we have to use another base for our estimation using coefficients, so i inspired myself from the alpha-beta filter and i started writing the code.
Calculation and The Estimation Coefficients
Simplicity is the key word, its also my signature style, if i want something good it should be simple enough, so my code look like that :
p = length/beta
a = close - nz(b ,close)
b = nz(b ,close) + a/p*gamma
3 line, 2 function, its a good start, we could put everything in one line of code but its easier to see it this way. length control the smoothing amount of the filter, for any filter f(Period) Period should be equal to length and f(Period) = p , it would be inconvenient to have to use a different length period than the one used in the filter we want to estimate (imagine our estimation with length = 50 estimating an ema with period = 100) , this is where the first coefficients beta will be useful, it will allow us to leave length as it is. In general beta will be greater than 1, the greater it will be the less lag the filter will have, this coefficient will be useful to estimate low lagging filters, gamma however is the coefficient who will estimate lagging filters, in general it will range around .
We can get loose easily with those coefficients estimation but i will leave a coefficients table in the code for estimating popular filters, and some comparison below.
Estimating a Simple Moving Average
Of course, the boxcar filter, the running mean, the simple moving average, its an easy filter to use and calculate.
For an SMA use the following coefficients :
beta = 2
gamma = 0.5
Our filter is in red and the moving average in white with both length at 50 (This goes for every comparison we will do)
Its a bit imprecise but its a simple moving average, not the most interesting thing to estimate.
Estimating an Exponential Moving Average
The ema is a great filter because its length times more computing efficient than a simple moving average. For the EMA use the following coefficients :
beta = 3
gamma = 0.4
N.B : The EMA is rougher than the SMA, so it filter less, this is why its faster and closer to the price
Estimating The Hull Moving Average
Its a good filter for technical analysis with tons of use, lets try to estimate it ! For the HMA use the following coefficients :
beta = 4
gamma = 0.85
Looks ok, of course if you find better coefficients i will test them and actualize the coefficient table, i will also put a thank message.
Estimating a LSMA
Of course i was gonna estimate it, but this time this estimation does not have anything a lsma have, no moving average, no standard deviation, no correlation coefficient, lets do it.
For the LSMA use the following coefficients :
beta = 3.5
gamma = 0.9
Its far from being the best estimation, but its more efficient than any other i previously made.
Estimating the Quadratic Least Square Moving Average
I doubted about this one but it can be approximated as well. For the QLSMA use the following coefficients :
beta = 5.25
gamma = 1
Another ok estimate, the estimate filter a bit more than needed but its ok.
Jurik Moving Average
Its far from being a filter that i like and its a bit old. For the comparison i will use the JMA provided by @everget described in this article : c.mql5.com
For the JMA use the following coefficients :
for phase = 0
beta = pow*2 (pow is a parameter in the Jma)
gamma = 0.5
Here length = 50, phase = 0, pow = 5 so beta = 10
Looks pretty good considering the fact that the Jma use an adaptive architecture.
Discussion
I let you the task to judge if the estimation is good or not, my motivation was to estimate such filters using the less amount of calculations as possible, in itself i think that the code is quite elegant like all the codes of IIR filters (IIR Filters = Infinite Impulse Response : Filters using recursion) .
It could be possible to have a better estimate of the coefficients using optimization methods like the gradient descent. This is not feasible in pinescript but i could think about it using python or R.
Coefficients should be dependant of length but this would lead to a massive work, the variation of the estimation using fixed coefficients when using different length periods is just ok if we can allow some errors of precision.
I dont think it should be possible to estimate adaptive filter relying a lot on their adaptive parameter/smoothing constant except by making our coefficients adaptive (gamma could be)
So at the end ? What make a filter truly unique ? From my point of sight the architecture of a filter and the problem he is trying to solve is what make him unique rather than its output result. If you become a signal, hide yourself into noise, then look at the filters trying to find you, what a challenging game, this is why we need filters.
Conclusion
I wanted to give a simple filter estimator relying on two coefficients in order to estimate both lagging and low-lagging filters. I will try to give more precise estimate and update the indicator with new coefficients.
Thanks for reading !
Profitable Moving Average CrossoverHello friends,
I'm glad to introduce a powerful research and optimization tool that takes the classic moving average crossover concept to a new level. Instead of relying on guesswork or fixed MA types, it lets you objectively discover the most profitable moving average pair for any instrument and timeframe.
🛠 How It Works
Moving average crossovers are among the most popular trading systems. A buy signal occurs when a shorter (faster) moving average crosses above a longer (slower) one, and a sell signal when it crosses below. The system's responsiveness — and the number of generated signals — depend on the chosen MA lengths and types.
This script evaluates 61 moving average types (including Jurik, Kaufman, Ehlers, Apirine, and others) and backtests all possible crossover combinations either across the entire chart history or within a custom backtest window . It then plots continuous profit metric lines for each crossover type and displays the top 5 performers in a results table. Each MA type is color-coded, allowing quick visual identification of which systems have historically delivered the strongest results.
🔥 Key Features
Pine Script V6 — optimized for performance and stability
Tests 61 moving average types , from classic to adaptive designs
Custom Backtest Window — analyze the entire history or a specific date range
Continuous profit curves for every crossover type plotted on chart
Top 5 crossover systems displayed in a compact summary table
Color-coded MA identifiers for fast visual comparison
Supports custom parameters for advanced MAs (JMA, ALMA, McGinley Dynamic, Adaptive Laguerre Filter, etc.)
Works seamlessly across all assets and timeframes
NOTE: Results will vary across different tickers and timeframes. Seeing strong performance in one preview does not imply similar profitability elsewhere — this variability is normal due to differing market structures.
NOTE 2: You can experiment with the tool independently or request a full study, in which case I'll share a spreadsheet of all backtest results with you.
👋 Good luck and happy trading!
Script payant
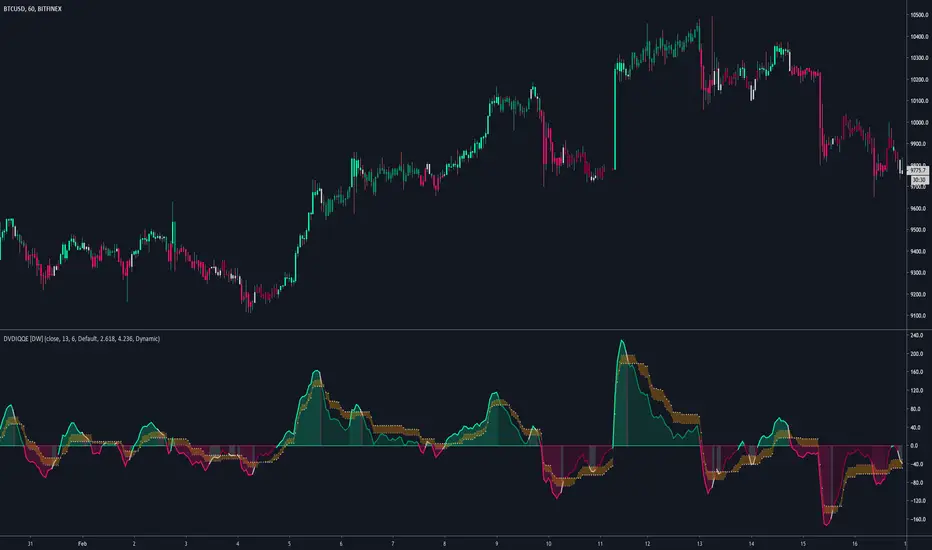
DVDIQQE [DW]This is an experimental study inspired by the Quantitative Qualitative Estimation indicator designed to identify trend and wave activity.
In this study, rather than using RSI for the calculation, the Dual Volume Divergence Index oscillator is utilized.
First, the DVDI oscillator is calculated by taking the difference between PVI and its EMA, and NVI and its EMA, then taking the difference between the two results.
Optional parameters for DVDI calculation are included within this script:
- An option to use tick volume rather than real volume for the volume source
- An option to use cumulative data, which sums the movements of the oscillator from the beginning to the end of TradingView's maximum window to give a more broad picture of market sentiment
Next, two trailing levels are calculated using the average true range of the oscillator. The levels are then used to determine wave direction.
Lastly, rather than using 0 as the center line, it is instead calculated by taking a cumulative average of the oscillator.
Custom bar colors are included.
Note: For charts that have no real volume component, use tick volume as the volume source.
Quantitative Qualitative Estimation (QQE)The indicator QQE, is an interesting tool based on a Relative Strength Index (RSI). While the original RSI is often used as a pointer for overbought or oversold market phases, the QQE provides additional information. Use the QQE to display trend direction and trend strength .
For me this is one of the most important indicator for Trend Following.
##This QQE indicator is an improved version made by 'mladen' for Metatrader 4.
The histogram does not differ from the original QQE! The developer has adapted the scaling so that the central horizontal level is zero. It has no effect to the result, but is much more convenient to analyze the trend.
Main Signals
Background changes when the black line crosses the grey line.
Identify the trend direction
Singal turns green while the main QQE trendline is above the zero line and red while it is below.
This works best in the major timeframes like Daily or Weekly.
You can activate this signal in the settings.
NYSE:THO
Identify the trend strength
_Histogram Colors_
Green (above 10): bullish
Red (below -10): bearish
Yellow: flat
It is not a buy or sell signal when the color of the histogram changes. It only says that one side could gained the advantage.
If you use a large timeframe like Monthly, you can reduce the number of false signal by setting the SF (Slow Factor) from 5 (default) to 1.
S&P 500, Monthly
Please always remember, there is no holy grail indicator!
...but this one defines trends quite accurately.

Price Regression AgreggatorPrice Estimator with aggregated linear regresion
---------------------------------------------------------------------------
How it works:
It uses 6 linear regression from time past to get an estimated point in future time, and using transparency, those areas that are move "visited" by those 6 different regressions and maybe more probable to be visited by the price (in fact if you zoom out you will see that price normally is around the lighter zones) have more aggregated painted colors, the transparency is lower and well, the lighter area should be more probable to be visited by the price should we put any faith on linear regression estimations and even more when many of them coincide in several points where the color is more aggregated.
If the "I" (the previous regressions increment) is too low, then we will have huge spikes as the only info gathered from the oldest linear regresssion will be within the very same trend we are now, resulting in "predictions" of huge spikes in the trend direction. (all regressions estimating on a line pointing to infinite)
If the "I" is high enough (not very or TV won't be able to display it) then you will get somewhat a "vectorial" resultant force of many linear regressions giving a more "real prediction" as it comes from tendencies from higher timeframes. E.g. 12 hours could be going down, 4h could be going sideways, 30m could be going up.
contact tradingview -> hecate . The idea and implementation is mine.
Note: transparency + 10 * tranparencygradient cannot be > 100 or nothing will be displayed
Note2: if the Future increment (how many lines are displayed to the right of the actual price ) are excessive, it will start to do weird things.
Note3: two times the standard deviation statistically correponds to a probability of 95%. We are calculating Top and Bot with that amount above and below. So anything inside those limits is more probable and if we are out of those limits it should fall back soon. Increase the number of times the std deviation as desired. There are calculators in the web to translate number of times std dev to their correspondent probability.
Note4: As we use backwards in time linear regressions for our "predictions" we lose responsiveness. Those old linear regressions are weighted with less value than more recent ones.
Note5: In the code i have included many color combinations (some horrible :-) )
Note6: This was an experiment while i was quite bored although ended enjoying playing with it.
Have fun! :-)
I leave it here because i am getting dizzy.
